CaseSanitizer
Studienprojekt von Hanna Peters und Youssef Sammari
SS 2003
Lehrstuhl Computerlinguistik
Universität Heidelberg
Betreuer: Dr. Markus Demleitner
Abstract
Der CaseSanitizer ist ein Programm, das durch die Identifizierung der in einem Text vorkommenden Abkürzungen und Namen eindeutige Satzgrenzen bestimmt. Das Verfahren arbeitet dokument-zentriert, d.h. unter Berücksichtigung des lokalen Kontextes und der Wortwiederholungen. Die Idee dabei ist, dass man zwischen eindeutigem Wortvorkommen (d.h. das Wort steht nicht nach einem potentiellen Satzende) und mehrdeutiger Wortposition im Satz unterscheidet. Da man die eindeutig vorkommenden Worte als Eigennamen oder gewöhnliche Worte klassifizieren kann, ist es dann möglich, Aussagen über dasselbe Wort in einer mehrdeutigen Situation zu treffen. Der große Vorteil bei diesem Verfahren ist, dass man nicht mehr auf Methoden der Statistik oder auf spezialisierte Grammatiken zurückgreifen muss.
Einleitung
Das ist ein Bsp. dafür, warum es schwierig ist Satzgrenzen richtig zu bestimmten. Prof. Becker erkannte, dass das Wissen über Abk. ausreichend ist, dies gilt aber nicht i. A. Die Forschung ging weiter und am 25. Juni 1999 kam es zu bahnbrechenden Erfolgen.
Würde man strikt nach dem Muster der Satzendezeichen : . , ! und ? vorgehen, dann hätte man folgende Aufteilung der Sätze.
Das ist ein Bsp.
dafür, warum es schwierig ist Satzgrenzen richtig zu bestimmten.
Prof.
Becker erkannte, dass das Wissen über Abk.
ausreichend ist, dies gilt aber nicht i.
A.
Die Forschung ging weiter und am 25.
Juni 1999 kam es zu bahnbrechenden Erfolgen.
Diese Aufteilung ist offensichtlich nicht korrekt, da die Abkürzungszeichen als Satzbegrenzungszeichen interpretiert werden!
Hätte man nun Informationen über die Abkürzungen, so bekommt man folgende Aufteilung:
Das ist ein Bsp. dafür, warum es schwierig ist Satzgrenzen richtig zu bestimmten.
Prof. Becker erkannte, dass das Wissen über Abk. ausreichend ist, dies gilt aber nicht i. A. Die Forschung ging weiter und am 25. Juni 1999 kam es zu bahnbrechenden Erfolgen.
Wir haben nun zwar alle Abkürzungen erkannt, aber trotzdem ist die Aufspaltung in einzelne Sätze noch nicht ganz gelungen. Informationen über Abkürzungen bringen uns dem Ziel schon relativ nahe, allerdings gibt es mit dem obigen 2. Satz noch ein Problem. In diesem Beispiel wird bei i. A. keine Satzgrenze, sondern nur eine Abkürzung erkannt. Um nun exakt Satzgrenzen zu erkennen, muss das System nicht nur Abk. erkennen , sondern es muss auch über Informationen über das darauffolgende Wort verfügen, um zu entscheiden, ob es sich nach der Abk. um eine Satzgrenze handelt oder nicht.
Würde in diesem Fall das System wissen, dass das ein gewöhnliches Wort ist, dass normalerweise kleingeschrieben und nur am Satzanfang großgeschrieben wird, dann hätten wir endlich die richtige Aufteilung der Sätze!
Im allgemeinen gilt für die Bestimmung von Satzgrenzen
Fehlerrate* unseres Verfahrens Bei vollständigem Wissen über 0.01-0.13% Abk. und Namen 1.20 % Abk., aber Namen per lexikon-lookup 0.45 % Namen, aber Abk. heuristisch
( * ) Die Fehlerrate gibt das Verhältnis der falsch zugewiesenen Wörter zur Gesamtmenge aller vom System zugewiesenen Wörter an. Quelle: Mikheev „Periods, Capitalized Words, etc.“ Also: je besser wir Namen und Abkürzungen bestimmen desto genauer können wir Satzgrenzen bestimmen!!!
Bei zu langen Texten kann es zu Wortwiederholungen kommen, die den dokumentzentrierten Ansatz nicht mehr unterstützen, daher bietet es sich für bessere Ergebnisse an, ab einer Textlänge von 4000 Worte zu unterteilen und getrennt weiter zu arbeiten. (Dies kann gut an einem Absatz geschehen, da dort ja mit Sicherheit ein Satzende vorliegt. )
Zu kurze Texte, unter 50 Worte, (z. B. Anschreiben) haben nicht genug Worte, um eine Abkürzung wie z. B. „Dr.“ zu erkennen. Daher arbeiten wir mit unterstützenden Ressourcen, in denen z. B. die wichtigsten Abkürzungen festgehalten sind.
- Textnormalisierung
- Bestimmung von Satzgrenzen
- Identifizierung von Abkürzungen
- Identifizierung von Eigennamen
- Robustes und flexibles Programm
- Insgesamt möglichst geringe Fehlerrate, d.h. hohe Erkennungsrate von Eigennamen und Abkürzungen
- Nur von wenigen externen Ressourcen abhängig
- Adaptivität an neue Sprachen
- Domänenunabhängig
Struktur der Komponenten
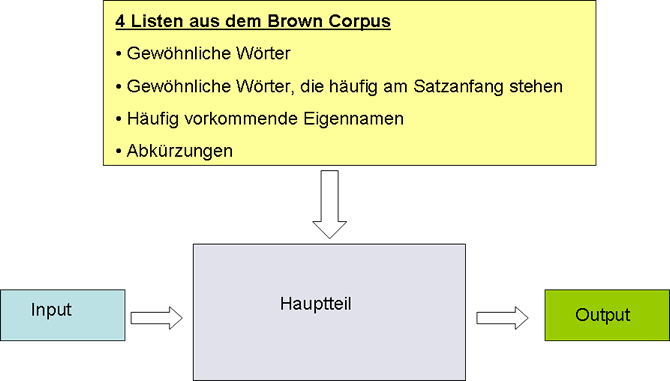
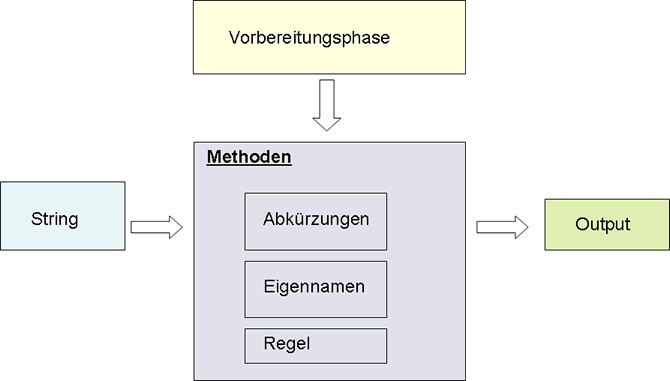
Für die Implementierung des CaseSanitizers ist folgende Struktur vorgesehen. Das Programm besteht aus 4 Komponenten:
- Vorbereitungsphase: Für die Identifizierung
der Abkürzungen und Eigennamen benötigen wir 4 Wortlisten:
- Gewöhnliche Wörter
- Gewöhnliche Wörter, die häufig am Satzanfang stehen
- Häufig vorkommende Eigennamen
- Häufig vorkommende Abkürzungen
Diese Listen werden aus dem Reuters
Corpus erstellt. Der Reuters Corpus besteht hauptsächtlich aus kurzen englisch-sprachigen Nachrichten-Texten in XML-Format.
- Input: Der bearbeitende Text wird dem Hauptteil als
ein nullterminierter String übergeben.
- Hauptteil: Im Hauptteil wird der Input dann nach
bestimmten Regeln in einzelne Sätze unterteilt. Dabei erstellen
wir intern einen Array von char-Pointern, so dass das (n-1)-te Arrayelement
auf das n-te Wort des Textes zeigt, so dass wir schneller mit dem Text
arbeiten können. Die Unterteilung in einzelne Sätze und die
Anwendung der Regeln, wie beispielsweise Identifizierung der Abkürzungen
übernehmen mehrere Funktionen.
- Output: Anschließend gibt das Programm den normalisierten Text aus.
Graphische Darstellung der Struktur



Allgemeine Regeln zur Satzgrenzenbestimmung
-
Zur Bestimmung von Satzgrenzen gibt es folgende Grundregeln:
- Steht ein Punkt nach einer Nicht-Abkürzung, so handelt es sich hierbei um eine Satzgrenze
- Steht ein Punkt nach einer Abkürzung und gleichzeitig an einem Absatzende, so handelt es sich hierbei sowohl um eine Satzgrenze als auch um eine Abkürzungsbegrenzung.
- Steht ein Punkt nach einer Abkürzung und das darauffolgende Wort ist kleingeschrieben, so handelt es sich hierbei um eine Abkürzung.
- Steht ein Punkt nach einer Abkürzung und vor einem großgeschriebenem Wort, dass kein Eigenname ist, so handelt es sich hierbei um eine Satzgrenze und um eine Abkürzung.
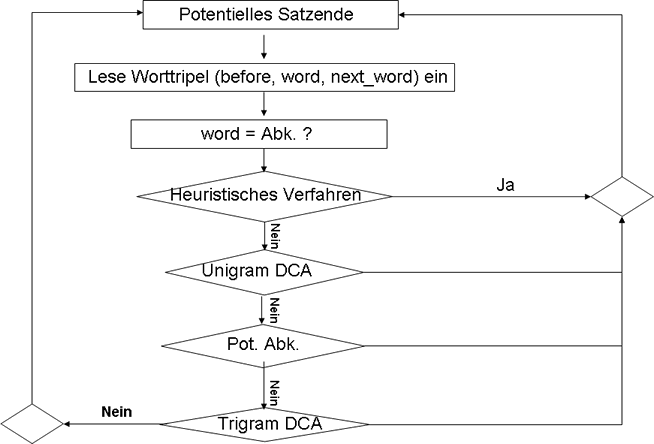
Identifizierung der Abkürzungen
- Heuristisches Verfahren:
- Lese bei jedem potentiellen Satzende das Wortpaar (before, word, next_word) ein
- Es handelt sich bei word dann um eine Abk., falls
- Es in der Liste der Abkürzungen steht
- Es keine Vokale besitzt (Mr., Dr., kg.) und nicht nur aus Großbuchstaben
besteht
(Bsp. Akronyme, Firmennamen) - Es aus nur einem Großbuchstaben besteht und danach ein Punkt folgt
- Es aus einer Folge von Großbuchstaben besteht, die durch
je einen Punkt getrennt sind (Y.M.C.A)
- Unigram DCA ( Document-Centered Approach)
- Besteht word aus weniger als 5 Buchstaben, dann speichere es als potentielle Abk.
- Ansonsten klassifiziere word als Nicht-Abk. und gehe
zum nächsten potentiellen Satzende
- Potentielle Abkürzungen
- Nach komplettem Textdurchlauf werden alle pot. Abk. sortiert
- Suche alle Wortpaare (before, word) der potentiellen Abkürzungen und Abkürzungen im Text.
- Betrachte before und klassifiziere das Wortpaar (before, word) und word wie das before klassifiziert wurde (siehe Unterpunkt).
- Es handelt sich um eine Abk., falls next_word :
- Ein klein geschriebenes Wort ist
- Eine Nummer
- Ein Komma
- Die dann noch unklassifizierten potentiellen Abkürzungen
klassifiziere als gewöhnliche Worte
- Bigram DCA
- Wenn nun für eine Abkürzung unterschiedliche Klassifizierungen
da sind, betrachte den jeweiligen Kontext (before) und
entscheide dementsprechend.
Bsp.: Vitamin C vs. John C.
» Bigram Vitamin C und Uni gram C als gewöhnliches Wort speichern
» Bigram John C. und Unigram C. als Abkürzung speichern
Bei der Klassifizierung von before geht man folgendermaßen vor:- Ist die Position eindeutig, so entscheidet die Groß- bzw. Kleinschreibung, ob es sich um einen Eigennamen oder ein gewöhnliches Wort handelt.
- Falls es ein Eigenname ist, prüfe, ob word eine Abkürzung ist (häufig der Fall). Dann speichere (before, word) als Namens-Abkürzung ab.
- Ist die Satzposition von before mehrdeutig, so
ist before identisch mit einem word.
Ausgehend vom obigen Beispiel: "Vitamin C" vs. "John C."
Falls nun beide Phrasen, also "Vitamin C" und "John C." in einem Text vorkommen, dann würde das Programm das Bigram"Vitamin C" und das Unigram C als gewöhnliches Wort speichern. Im anderen Fall wird "John C" und C als Namens-Abkürzung gespeichert. Da in diesem Fall widersprüchliche Information über C vorliegen, reicht es nicht aus nur Abkürzung allein zu betrachten. Deshalb können wir nur mit Hilfe des Kontextes entscheiden, wie und an welcher Stelle klassifiziert werden soll.
Die Frage, ob „... vitamin C. Research ...“ einen Satzbeginn enthält, kann nun geklärt werden:
C. ist in diesem Zusammenhang ein gewöhnliches Wort und damit ist, falls Research kein Name ist, nach C ein Satzende - Wenn nun für eine Abkürzung unterschiedliche Klassifizierungen
da sind, betrachte den jeweiligen Kontext (before) und
entscheide dementsprechend.
Datenstruktur zur Identifizierung der Abkürzungen
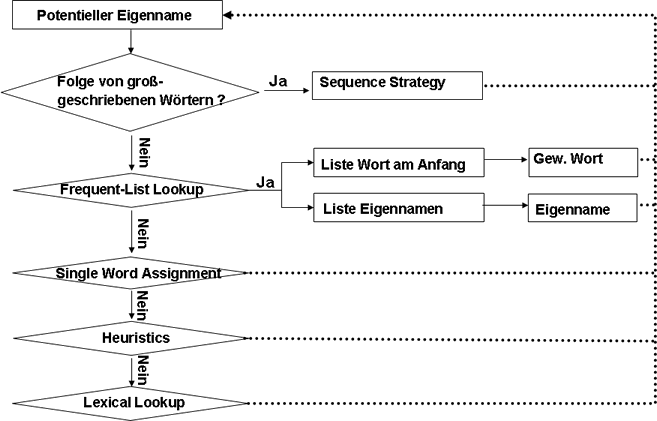
Identifizierung der Eigennamen
Folgende Regeln werden zur Identifizierung der Eigennamen angewandt:
- Sequenz Strategie
- Extraktion einer Folge von großgeschriebenen Wörter
aus einer nicht-ambigen Position
- Rocket System Development Co.
- Generierung von Teilketten
- Rocket System
- Rocket System Co.
- Klassifizierung als Eigennamen, falls Teilketten in ambiger Position
vorkommen
Dieses Verfahren eignet sich auch zur Disambiguierung von gewöhnlichen Wörtern.
- Extraktion einer Folge von großgeschriebenen Wörter
aus einer nicht-ambigen Position
- Frequent-List Lookup Strategie
- Es werden 2 Listen aus dem Text generiert
- Eine Liste mit normalen Wörtern, die häufig am Satzanfang stehen.
- Eine Liste mit häufig vorkommenden Eigennamen
- Es werden 2 Listen aus dem Text generiert
- Single Word Assignment
- Falls ein Wort in nicht-ambigen Positionen immer großgeschrieben wird, so handelt es sich hierbei um einen Eigennamen
- Falls ein Wort in nicht-ambigen Positionen immer kleingeschrieben
wird , so handelt es um ein gewöhnliches Wort
- Heuristisches Verfahren
- Ein einzelnes groß geschriebenes Wort in Klammern oder in
Zitaten
- John (Cool) Lee
- Falls nach Kleinschreibung, Nummer oder Komma ein Klammer folgt
und das erste Wort ist groß geschrieben
- … happened(Moscow…) but …
- Nach einer groß geschriebenen Abk. folgt ein groß
geschriebenes Wort und dieses Wort ist nicht in der Liste der häufig
am Satzanfang vorkommenden Wörtern enthalten
- Dr. Peter
- Dr. Peter
- Lexical-Lookup Strategie
Die restlichen ambigen Wörter werden mit der Liste der gewöhnlichen Wörter verglichen. Kommen diese in der Liste nicht vor, so werden sie als Eigennamen klassifiziert.
Folgende heuristische Regeln bestimmen einen Eigennamen:
Datenstruktur zur Identifizierung der Eigennamen