(V-1) eine dem Anfangssymbol der Grammatik entsprechende Vorsegmentierung des
Eingabetextes (also z. B. Eingabe satzweise).
(V-2) ein Lexikon, mit dessen Hilfe den Elementen der Eingabe (in der
Regel den Wörtern) grammatische Kategorien zugewiesen werden (in der
Lexikonphase).
(V-3) ein Eingabebereich, in dem die den Elementen zugewiesenen
Kategorien in der Reihenfolge der Eingabe gespeichert werden.
(V-4) die Menge der Ersetzungsregeln einer kontextfreien
Phrasernstrukturgrammatik.
(V-5) eine Steuertabelle, bestehen aus einer Matrix aus Zuständen und
lexikalischen Symbolen (der Aktionstabelle) sowie einer Matrix aus
Zuständen uns nicht-lexikalischen Symbolen (der Sprungtabelle). Die Felder
der Tabellen entfalten Anweisungen für den Parser. Zu den lexikalischen
Symbolen kommt das Zeichen "$" als Markierung des Eingabeendes
hinzu.
(V-6) eine Arbeitsbereich, der als Graph vorgestellt werden kann,
dessen Knoten mit Nummern von Zuständen und dessen Kanten mit
Listen etikettiert sind. Die Knoten entsprechen zugleich bestimmten
Punkten in der Eingabe. Die Listen sind die vorläufigen Analyseergebnisse
für die Zeichenkette zwischen zwei Punkten. Zu Beginn enthält der
Arbeitsbereich nur einen Knoten für den Zustand 0 und keine Kanten.
(V-7) eine Variable für den aktuellen Zustand des Parsers, die zu Beginn den
Wert 0 hat.
(V-8) eine Variable, die die aktuelle Position in der Eingabe bezeichnet und
zu Beginn den Wert 0 hat.
Beispiel: Regeln, nach denen reduziert wird
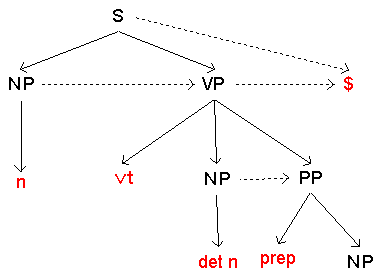
(re1) S -> NP VP
(re2) VP -> vi
(re3) VP -> vt NP
(re4) VP -> vt NP PP
(re5) NP -> n
(re6) NP -> det n
(re7) NP -> det adj n
(re8) PP -> präp NP
Beispiel: Lexikon
vi = {rechnen, antworten}
vt = {verarbeiten, erzeugen}
det = {die, keine}
adj = {beliebigen}
n = {computer, eingaben, regeln, antworten, erzeugen, disketten}
präp = {auf, nach}
Es gibt manche Zustände während der Verarbeitung der
einzelnen Regeln der Grammatik, die die Unterschiede zeigen, wie viele
unmittelbaren Konstituenten schon gesehen worden sind, und wie viele
Konstituente noch folgen.
Man markiert die Grenze zwischen abgearbeiteten und doch abzuarbeitenden
Konstituenten durch einen Punkt, so gibt es z.B. zu einer Regel der
Form X -> YZ folgende Zustände:
X -> . XY
X -> Y . Z
X -> YZ .
Derselbe
Zustand bzw. dieselbe Position im Input wird zu allen Regeln, die in der
rekursiven Expansion der Symbole hinter dem Punkt verwendet werden können, projiziert.
Die Menge aller Zustände erhält man, indem man zunächst der Grammatik eine
Regel hinzufügt, in der man den Zustand (Z-0) vor Beginn des Parsers des Startsymbols
S´ der Grammatik markiert.
Zustand 0: S´-> . S
Derselbe Zustand, d.h. eine Abarbeitungssituation an derselben Stelle in der Eingabekette, läßt sich in alle Regeln projizieren, die zur rekursiven Expansion des Symbols hinter dem Punkt benutzt werden können, also z. B.
S´
-> .
NP VP
NP
-> .
n
NP ->
. det n
NP
-> . det adj n
Den nächsten Zustand ermittelt man, indem man den Punkt um eine Konstituente weiter schiebt. Aus (Z-0) ergibt sich
Zustand 1: S´ -> S.
Eine Projektion in weitere Regeln ist hier nicht möglich, da sich rechts des Punktes keine Konstituente mehr befindet. Nun fährt man fort, die übrigen Regeln in abarbeitungsphasen zu zerlegen. Da der Zustand vor Beginn der Anwendung einer Regel schon in einer vorangehenden Projektion enthalten ist, braucht man jetzt immer erst mit dem Zustand nach Abarbeitung der ersten Konstituente zu beginnen. Soweit die Zerlegungen zweier Regeln der Grammatik übereinstimmen, werden sie demselben Zustand zugeordnet; vgl. unten Zustände 7 und 10.
Zustand 2: S -> NP . VP
VP -> . vi
VP -> . vt NP
VP -> . vt NP PP
Zustand 3: NP -> n .
Zustand 4: NP -> det . n
NP -> det . adj n
Zustand 5: S -> NP VP .
Zustand 6: VP -> vi .
Zustand 7: VP -> vt . NP
VP -> vt . NP PP
NP -> . n
NP -> . det n
NP -> . det adj n
Zustand 8: NP -> det n .
Zustand 9: NP -> det adj . n
Zustand 10: VP -> vt NP.
VP
-> vt NP. PP
PP -> . präp PP
Zustand 11: NP -> det adj n .
Zustand 12: VP -> vt NP PP.
Zustand 13: PP -> präp . NP
NP -> . n
NP -> . det n
NP -> . det adj n
Zustand 14: PP -> präp NP.
Zur Ermittlung der betreffenden Spalten benutzt man zwei
Funktionen, FIRST und FOLLOW. FIRST ergibt zu jeder
nicht-terminalen Kategorie die Menge der ersten unmittelbaren lexikalischen
Konstituenten, FOLLOW ergibt die Menge der möglichen nachfolgenden
Konstituenten.
FIRST ($) = $
FIRST (VP) = vi, vt
FIRST (NP) = det, n
FIRST (PP) = präp
FOLLOW(S) = $
FOLLOW(VP) = FOLLOW(S) = $
FOLLOW(NP) = VP
FOLLOW(NP) = FOLLOW(VP) = $
FOLLOW(NP) = PP
FOLLOW(NP) = FOLLOW(PP) = FOLLOW(VP) = $
FOLLOW(PP) = FOLLOW(VP) = FOLLOW(S) = $
(Siehe unten Spezifikation, Funktion: first + follow
berechnen)
a. shift
eintragen in Aktionstabelle
b. goto eintragen in Sprungtabelle
c. reduce eintragen in Aktionstabelle
(Siehe unten Spezifikation, Funktion:
Shift, Goto, Reduce eintragen)
Die Zustände (Z-0) bis (Z-14) bilden die Zeilen der
Aktionstabelle und der Sprungtabelle. Die Spalten der Aktionstabelle sind
mit den lexikalischen Kategorien und '$' (für das Eingabeende)
indiziert, die Spalten der Sprungtabelle mit
den nicht-lexikalischen Kategorien der Grammatik.
a. shift eintragen in
Aktionstabelle.
Soweit in der
obigen Kollektion von Zustandsbeschreibungen ein Punkt vor einer lexikalischen
Kategorie steht, wird in der entsprechenden Spalte des betreffenden Zustands in
der Aktionstabelle 'shz'(shift) eingetragen. Dabei ist z die Nummer
derjenigen Zustandes, der eine Zerlegung derselben Regel darstellt, nur dass der
Punkt über die lexikalische Kategorie hinweg vorgerück ist.
b. goto eintragen in Sprungtabelle.
Soweit in
der obigen Kollektion von Zustandsbeschreibungen ein Punkt vor einer
nicht-lexikalischen Kategorie steht, wird in der entsprechenden Spalte des
betreffenden Zustandes in der Sprungtabelle 'goz'(goto) eingetragen.
Dabei ist z die Nummer desjenigen Zustandes, der eine Zerlegung derselben
Regel darstellt, nur daß der Punkt über die nicht-lexikalische Kategorie
hinweg vorgerückt ist.
c. reduce eintragen in
Aktionstabelle.
Soweit in der obigen Kollektion von Zustandsbeschreibungen ein Punkt am
Ende einer Produktion steht, wird in der Zeile des betreffenden Zustands in der
Aktionstabelle 'rer'(reduce) eingetragen, und zwar in all denjenigen
Spalten, deren Kategorie die erste lexikalische Kategorie einer Konstituente
ist, die aufgrund der Regeln auf die Kategorie X folgen kann. Dabei ist r
die Nummer der Produktion in der Grammatik und X die Kategorie dieser
Produktion. Kommt X auch am Ende einer mit der Grammatik erzeugbaren
Ableitung vor, so wird ein gleicher Eintrag in der Spalte mit dem Etikett '$'
gemacht.
In der Spalte $ der Zustände, mit denen eine S'-Produktion zu
Ende geführt ist, wird 'accept' eingetragen. (Weitere Agorithmen
dazu findet man in Aho/Sethi/Ullman 1986, 221ff.; Mayer 1978, 278ff. 353ff.)
AKTIONSTABELLE:
| Zst | vi | vt | det | adj | n | präp | $ |
| 0 | sh4 | sh3 | |||||
| 1 | acc | ||||||
| 2 | sh6 | sh7 | sh4 | sh5 | |||
| 3 | re1 | ||||||
| 4 | re2 | re2 | |||||
| 5 | sh10 | sh9 | |||||
| 6 | re3 | re3 | |||||
| 7 | sh16 | re4 | |||||
| 8 | re4 | ||||||
| 9 | re5 | re5 | re5 | re5 | |||
| 10 | sh12 | sh11 | |||||
| 11 | re6 | re6 | re6 | re6 | |||
| 12 | sh13 | ||||||
| 13 | re7 | re7 | re7 | re7 | |||
| 14 | sh16 | ||||||
| 15 | re8 | re8 | re8 | re8 | |||
| 16 | sh10 | sh9 | |||||
| 17 | re9 | re9 | re9 | re9 |
SPRUNGTABELLE:
| Z | NP | PP | VP | S |
| 0 | 2,14 | 1 | ||
| 1 | ||||
| 2 | 3,7 | |||
| 3 | ||||
| 4 | ||||
| 5 | 6,14 | |||
| 6 | ||||
| 7 | 8 | |||
| 8 | ||||
| 9 | ||||
| 10 | ||||
| 11 | ||||
| 12 | ||||
| 13 | ||||
| 14 | 15 | |||
| 15 | ||||
| 16 | 14,17 | |||
| 17 |
(A-1) Konsultation der Tabelle: Es
wird das Feld in der Aktionstabelle aufgesucht, dessen Zeilennummer mit dem
Aktuellen Zustand des Parsers übereinstimmt, und dessen Spalte mit dem gleichen
Symbol etikettiert ist, das sich an der nächsten Position hinter der aktuellen
Position in der Eingabe befindet. Ist die nächste Position das Ende der
Eingabe, so suche die Spalte mit dem Symbol '$' auf. Weiter
(A-2).
(A-2) Erfolgsprüfung: Ist das Feld leer, so weise die Eingabe
zurück und beende die Prozedur. Enthält das Feld den Eintrag 'accept',
so gebe die im Arbeitsbereich befindliche Liste als Ergebnis der Analyse aus und
beende die Prozedur. Sonst weiter (A-3)
(A-3) Hinzufügen: Enthält das Feld die Anweisung 'shift z'
(abgekürzt 'shz'), wobei z die Nummer eines Zustands ist, so
bilde eine Liste aus der Kategorie des nächsten Eingabeelements und füge diese
im Arbeitsbereich als Kante an den letzten Knoten an (der
den letzten aktuellen Zustand repräsentiert). Mache z zum neuen
aktuellen Zustand. Füge z als neuen Knoten dem
Arbeitsbereich hinzu und verbinde die neue Kante mit diesem
Zustand. Erhöhe die aktuelle Position um 1. Weiter (A-1).
(A-4) Reduktion: Enthält das Feld die Anweisung 'reduce r' (abgekürzt
'rer'), wobei r die Nummer einer Regel ist, so fasse die Listen im
Arbeitsbereich, deren oberste Elemente den unmittelbaren Konstituenten in der
Regel r entsprechen, zu einer neuen Liste unter der Kategorie der Regel
zusammen. (Dabei wird im Arbeitsbereich um soviele Knoten zurückgegangen,
wie Konstituenten zusammenzufassen sind.) Mach den Knoten, der der ersten
der zusammengefaßten Listen (also dem 'linken Aufhänger') vorangeht, zum
vorübergehenden Zustand. Hänge die neue Liste an diesen Knoten an.
Suche in der Sprungtabelle die Zeile mit dem vorübergehenden Zustand.
Hänge die neue Liste an diesen Knoten an. suche in der Sprungtabelle die
Zeile mit dem vorübergehenden Zustand auf. Entnehme der Spalte, die das
Etikett der gerade gebildeten neuen Konstituenten trägt, den Zustand z.
Mache z zum neuen aktuellen Zustand. Füge z als neuen
Knoten dem Arbeitsbereich hinzu und verbinde die neue Kante mit diesem
Knoten. Weiter (A-1).