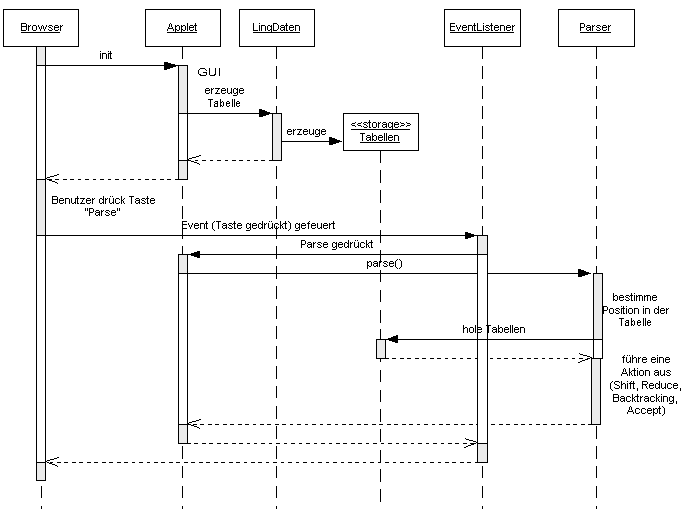
Das folgende Diagramm gibt eine Übersicht über den Standardablauf in einer Benutzersession mit dem Parserprogramm.
Demzufolge gehen die Aktionen vom Benutzer, der den Browser bedient, aus. Nach Abruf des Applets über die HTML-Seite, in der das <Applet>-Tag eingebettet ist, ruft der Browser die init-Methode des Applet auf. Hierdurch wird ein Objekt der Klasse LingDaten erzeugt. Hier wird für die aktuelle Grammatik und Lexikon die Zustände und die Tabellen erzeugt. Dann kehrt die Kontrolle zum Browser / Benutzer zurück.
Drückt der Benutzer die Taste "parse", dann wird Java-technisch gesprochen ein Event gefeuert. Der vorher auf den Knopf registrierte EventListener bekommt das Event zugestellt. Er stellt das Event weiter an das Applet. Das Applet seinerseits ruft nun den Parser mit der Methode parse() auf. Hier wird für den aktuellen Zustand (am Anfang immer Z0) und die aktuelle Eingabeposition die aktuelle Aktion aus der Tabelle (siehe Tabellenzugriff) geholt und ausgeführt.
Das folgende Diagramm zeigt den Funktionsbaum (die Hierarchie der Funktionen) für die Tabellenerzeugung (Klasse LingDaten, Methode erzeugeTabellen). Pfeile zeigen die Aufrufhierarchie bzw. Enthaltensein von Funktionalitäten in übergeordnete Funktionsblöcke an. Die dicken Pfeile zeigen die "Hauptlinie" des Programms, wo die besonders wichtigen Funktionen abgearbeitet werden.
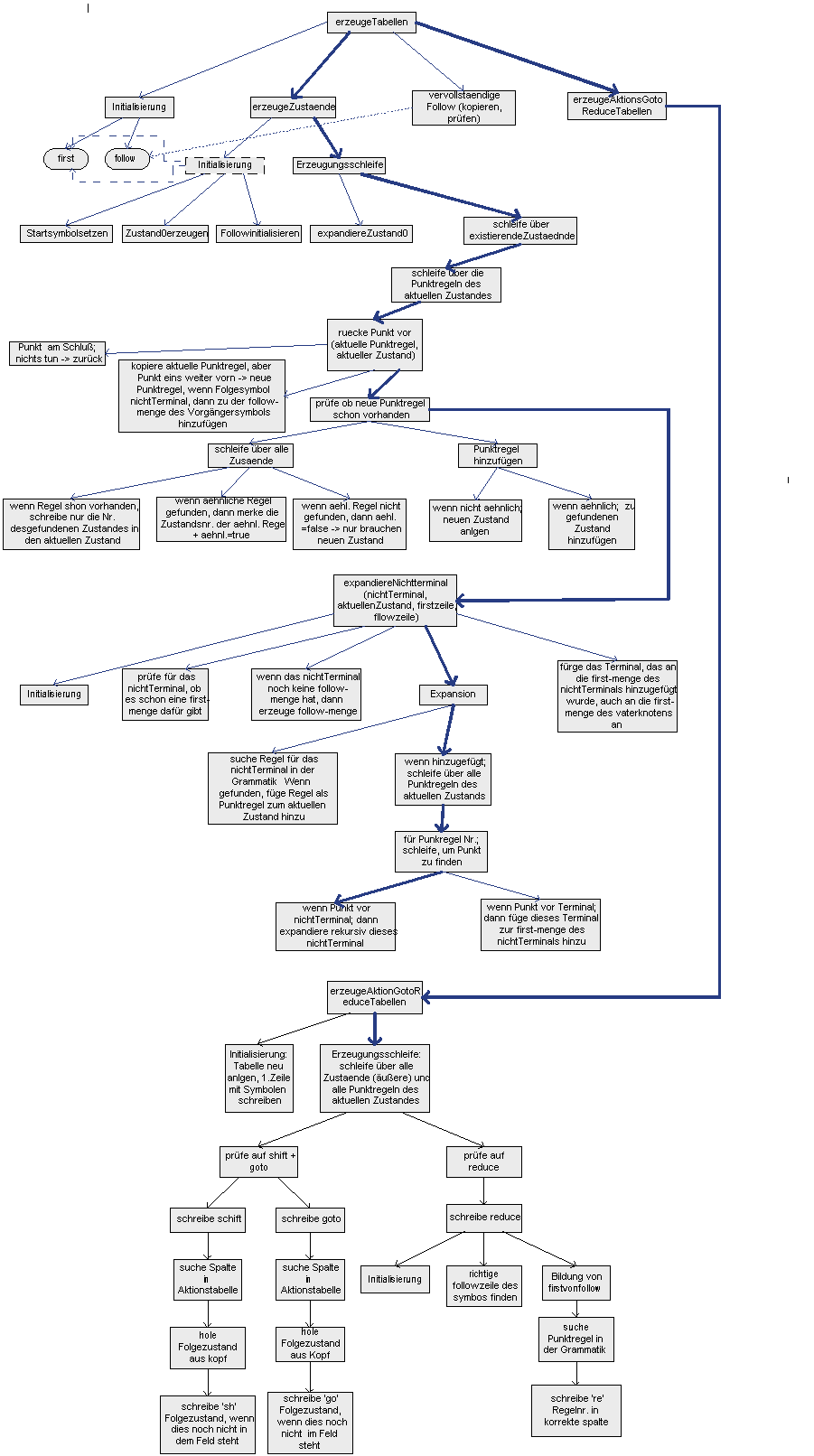
Die folgende Beschreibung ist nur eine Übersicht. Zur detaillierten Funktionsweise muss die Klassendokumentation des Quellcodes hinzugezogen werden. Für die Tabellenerzeugung siehe Klasse "LingDaten".
Die Wurzel des Baums ist somit die Methode "erzeugeTabellen". Von dort werden zuerst einige Initialisierungen durchgeführt (First und Follow, Erzeugung des allerersten Zustands Z0).
Danach geht das Programm in die Erzeugungsschleife zur Erzeugung aller Zustände. Dieser Prozess wird gestartet durch die Expansion des Zustands Z0, mit dem dieser Zustand abgeschlossen ist. Danach läuft die Schleife über die existierenden Zustände; diese Menge steigt stetig an, so dass die Schleife ein "dynamisches Ende" hat. Pro Zustand gibt es eine innere Schleife über die "Punktregeln" dieses Zustands.
In der inneren Schleife wird zuerst die aktuelle Punktregel kopiert und der Punkt um eine Stelle vorgerückt. Dann wird diese neue Punktregel geprüft: ist sie schon vorhanden? Wenn nein, wird noch ein Test auf "Ähnlichkeit" gemacht. 2 Punktregeln sind genau dann ähnlich, wenn der Teil links des Punktes identisch ist. Wenn die Punktregel ähnlich ist, wird sie zu einem vorhanden Zustand hinzugefügt. Ist sie nicht ähnlich, so wird ein neuer Zustand erzeugt und die Punktregel hinzugefügt.
Anschliessend wird, wenn die Punktregel hinzugefügt wurde (existierender oder neuer Zustand), das Symbol hinter dem Punkt expandiert, wenn es ein Nichtterminalsymbol ist. Dies ist ein rekursiver Prozess (d.h. wird eine neue Punktregel hinzugefügt, die die gleiche Eigenschaft hat, wird rekursiv weiter expandiert). Schlussendlich wird noch die Fist-Menge des Nichtterminalsymbols erweitert, wenn der Punkt vor einem Terminalsymbol steht.
In der Methode "vervollständigeFollow" wird die Follow-Menge von Elternknoten auf die Kindknoten übertrage (d.h. bei Regeln der Form A --> B. wird Follow(B) = Follow(A) berechnet).
Danach wird aus den Zuständen die Tabellen (Aktions- und Sprung-) erzeugt. Die Erzeugungsschleife läuft über alle Zustände.
Der Fall shift und goto ist weitgehend gleich. Die Spalte wird bestimmt, und der im Kopf stehende Folgezustand wird in das Tabellenfeld geschrieben.
Für reduce wird vorher noch die Regelnummer aus der Grammatik bestimmt. Die Spalte bestimmt sich aus der First(Follow(X))-Menge, wobei X das Nichtterminalsymbol auf der linken Produktionsseite ist.
Das folgende Diagramm zeigt die Funktionsweise des Parsers. Wiederrum ist die Hauptlinie verstärkt gezeichnet. Mehrere Seitenlinien, die von der Hauptlinie abgehen, sind farbig markiert.
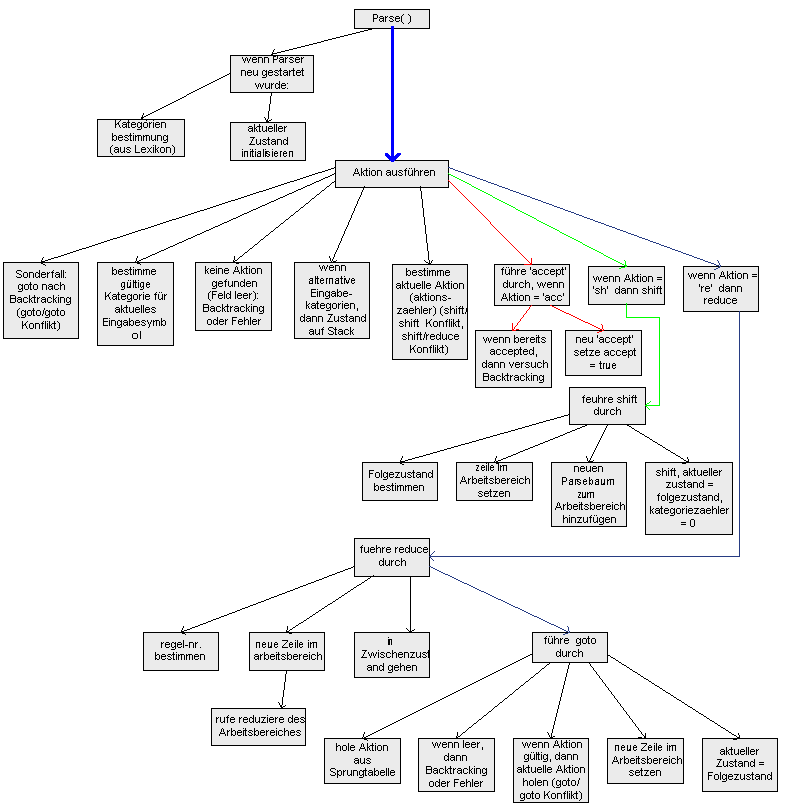
Wird der Parser neu gestartet, wird zuerst der Zustand initialisiert.
Ist der Parser im laufenden Zustand, wird (pro Aufruf) genau eine Aktion ausgeführt.
Für den Sonderfall, dass die letzte Aktion des Parsers ein Backtracking war in den Zustand, zu dem der Parser einen Goto/Goto-Konflikt hatte und die alternative Goto-Aktion auf den Stack gelegt hat, wird hier eine Goto-Aktion mit dem vom Stack geholten Zustand durchgeführt.
Ansonsten wird die aktuell gültige Eingabekategorie des aktuellen Eingabewortes bestimmt. Bei mehreren lexikalischen Kategorien kann dies dazu führen, dass in diesen Zustand ein Backtracking möglich ist, daher muss in diesem Fall der aktuelle Zustand auf den Stack gelegt werden.
Wurde keine Aktion bestimmt, ist das Parsing entweder gescheitert, oder wenn noch Alternativen auf dem Stack vorhanden sind, wird ein Backtracking durchgeführt.
Sind in dem bestimmten Feld der Tabelle mehrere Aktionen vorhanden, wird wiederrum eine gültige Aktion bestimmt und die nächste Alternative auf den Stack gelegt.
Nun folgt die eigentliche Aktionsbearbeitung. Im Falle von "acc" wird ein Flag gesetzt. Bei erneutem Parsen löst dieses Flag dann ein Backtracking aus, mit dem nach alternativen Lösungen gesucht werden kann.
Im Falle von Shift wird der Folgezustand bestimmt und als aktueller Zustand gesetzt.
Bei einem Reduce wird zuerst die Regelnummer bestimmt. Dann wird der Zustand im Arbeitsbereich angepaßt, d.h. die zu reduzierenden Symbole werden mit dem Vaterknoten zu einem neuen gemergten Baum vereinigt. Anschliessend wird in einen Zwischenzustand gegangen, und zwar der, der vor dem ersten reduzierten Symbol steht. Anschliessend wird ein goto ausgeführt.
Das Goto holt sich die Aktion von der Sprungtabelle. Die weiteren Aktionen ähneln dem Shift-Falle.