In the summer term of 2018 the ICL Heidelberg offered an advanced course on Neural Networks for Natural Language Processing. During this course we presented and discussed two papers on neural language generation.
Introduction
The two papers presented were ”Learning to Generate Product Reviews from
Attributes” by Dong et al. and ”Controlling Linguistic Style Aspects in Neural Language
Generation” by Ficler & Goldberg.
Both of these papers employ neural networks to generate product reviews. Their main differences are the
corpora they work on as well as the specific input they generate reviews from.
Dong et al. work on book reviews extracted from Amazon and Ficler & Goldberg work on movie reviews
extracted from Rotten Tomatoes.
While Dong et al. use basic metadata, such as userID and rating, as input for the neural net – Ficler
& Goldberg use style parameters to generate review sentences.
The discussion lead to the question whether a combination of these two approaches would be possible.
As either approach has specific advantages over the other a combination of these advantages would be of
interest.
In this blogpost I want to explore the possibility of combining the most interesting aspects of the two
approaches.
Papers
Dong et al.
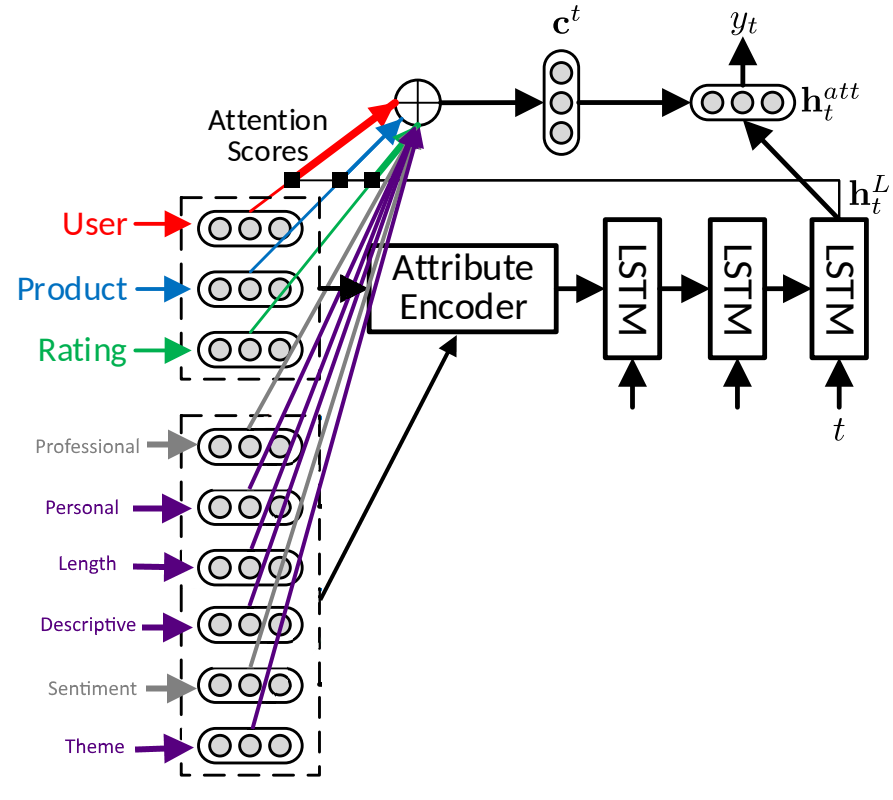
For their system trained on Amazon book reviews Dong et al. use three input components.
- UserID
- ProductID
- Rating
These three parameters are all retrieved directly from the Amazon metadata. The input is encoded by an attribute encoder and then fed into an RNN with LSTM units. The RNN is enhanced by the attention algorithm.

One of the problems of the system is the input limitating the information that can be
given to the system. The system can learn to generate a review for a certain product and user with
a certain rating, however there is no direct control over content or style.
Of course with the use of user profiling users who write in certain styles or discuss specific topics in
their reviews could be identified. The system, however cannot address these aspects directly.
Ficler & Goldberg
Ficler & Goldberg apply a similar approach, for generating reviews, also using an RNN
with LSTM units. However the two approaches differ in the input the system receives. While Dong et
al. uses User, Product and Rating, Ficler & Goldberg use different style features. The
system Ficler & Goldberg developed generates reviews based on these style aspects, on the other hand
disregards information about the product or theuser.
The specific style features are:
- Professional
- Personal
- Length
- Descriptive
- Sentiment
- Theme
The aspects “Professional” as well as “Sentiment” are retrieved by metadata provided by rottentomatoes.com. Where the former is based on the user profile and the latter on the rating of the review.
The other style aspects however cannot be retrieved from the metadata. Instead different heuristics are developed to automatically annotate the corpus.
“Length” is based on the length of a sentence, “Descriptive” on the ratio of adjectives and “Theme” on a list of words prototypical of a certain theme and their existence in a text.
The system as presented has a considerable potential to improve Dong et al.’s approach gaining a better control of the content and style of a generated review. However, not including the product or the user comes with some drawbacks. The system cannot learn any actual knowledge about the different products it is trained with. The system produces general text that is similar to a movie review however all information contained is not connected to an actual product as it is not possible to include product information in the input.
Combination
Since both systems work on different corpora it is not a simple and straightforward task
to combine the two systems.
Two approaches for combining the systems are conceivable.
Corpus Retagging
The first obvious approach is the reannotation of either of the corpora. For the Ficler & Goldberg approach, that uses data from Rotten Toamtoes, including the user and product in the input should be possible. These attributes could be extracted from the metadata in rottentomatoes.com, however this would require a complete reextraction and reprocessing of the corpus.
This method should also work for the approach by Dong et al.. The heuristics used in Ficler & Goldberg are based on the review texts and can be reapplied to automatically annotate the corpus. However, the heuristics would have to be adjusted to work on full reviews instead of single sentences.
The two aspects from Ficler & Goldberg, that concern metadata can be transferred. ‘Sentiment’ is included in the rating, as sentiment is only based on rating in the Ficler & Goldberg paper. ‘Professionalism’ is more complicated however. Rotten Tomatoes tags reviews by professional movie reviewers and reviewers, that are known for writing quality reviews. Ficler & Goldberg use these tags to mark reviews as professional. Amazon does not provide comparable tags for their reviews. However, Amazon has a rating system for reviews. Users can mark reviews as helpful and Amazon in turn has a section with high-rated reviews. On average these reviews are of higher quality, which could be used to model a tag similar to ‘Professionality’.
The text-based annotations ‘Length’, ‘Descriptive’, and ‘Theme’ are also
transferable. Length is easy to annotate. In order to work on full reviews and stay
true to the intention of capturing the writing style, the length feature should be
transfered to average sentence length. ‘Descriptive’ is based on the ratio of
adjectives that are contained in a review, that can also be computed for the data in the
Dong et al. corpus.
The theme of a review is tagged based on keyword dictionaries. These have been generated
specifically for the task. As these keyword dictionaries and themes are based on
movies, new themes and new corresponding themes would have to be generated in order to retag
the corpus.
Multi-Task Learning
The second possibility for the combination of the two systems is an approach based on multi-task learning in neural networks. The idea here is to add a second output layer to the system described in Dong et al.. Ruder does a good job at describing the possibilities of Multi task learning in An Overview of Multi-Task Learning in Deep Neural Networks. A Neural Network in this case is assigned multiple output layers and learns parameters on both data in a shared parameter space. This does not only improve performance but also gives the possibility to split a task up – as would be the case in the combination described in this blogpost.
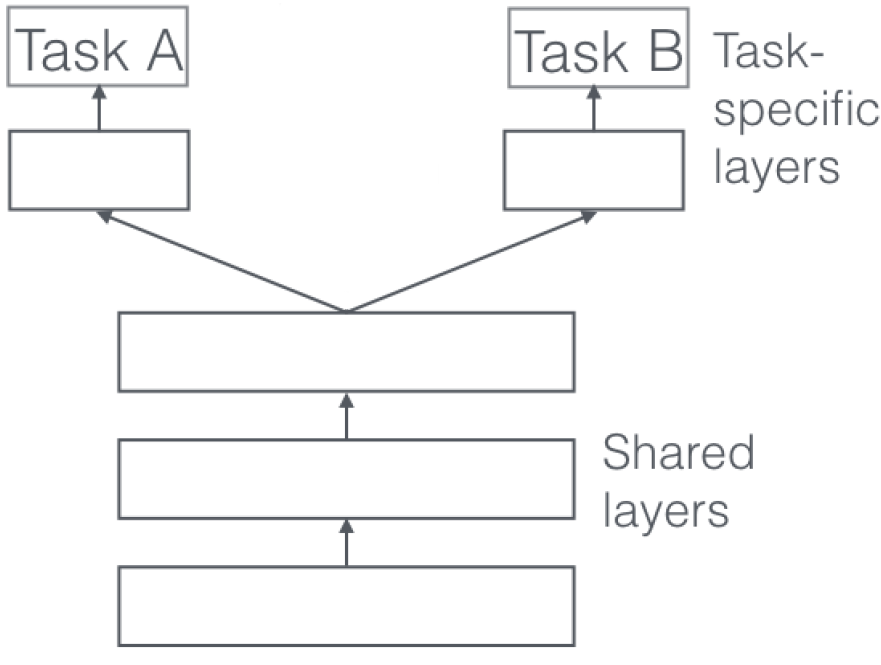
The differences in the two datasets could be a problem for a multi-task learning system as the Rotten Tomatoes dataset has been split into single sentences, while the Amazon dataset consists of full reviews. Additonally the theme aspect would still have to be remodeled as it is too movie specific for a combined task.
Conclusion
Sources
Dong, Li, et al. “Learning to generate product reviews from attributes.” Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers. Vol. 1. (2017).
Ficler, Jessica, and Yoav Goldberg. “Controlling linguistic style aspects in neural language generation.” arXiv preprint arXiv:1707.02633 (2017).
Ruder, Sebastian. “An overview of multi-task learning in deep neural networks.” arXiv preprint arXiv:1706.05098 (2017).



