What does adversarial mean in NLP?
In the past two years, machine learning, particularly neural computer vision and NLP, have seen a tremendous rise in popularity of all things adversarial. In this blog post I will give an overview of the two most popular training methods that are commonly referred to as adversarial: Injecting adversarial examples (1) and min-max optimization (2). After showcasing how they are applied in NLP I will compare them and examine ways to combine them (3).
1 Beware of adversarial examples!
Szegedy et al. (2014)1 first introduced what they called an “intriguing property of neural networks”: Adding a specific layer of noise – imperceptible to the human eye – to images that are labeled correctly with high confidence can cause state-of-the-art neural image classification systems to misclassify the perturbed image.

The existence of such adversarial examples has challenged the Deep Learning community ever since. First of all, they demonstrate that neural networks severely lack robustness even in the immediate vicinity of data points on which they perform well. Instead of being able to predict confidently in these areas, they fail on certain points in the input space which, like miniature black holes, make the input-output mapping highly discontinuous where it shouldn’t be. Secondly, these holes are not random artifacts of the learning process that affect one particular model only. Models trained on a different subset of the training data will often be vulnerable to the same adversarial examples, even though they may predict a different false label.2 Exhaustively searching the input space for such data points amounts to a computationally costly optimization problem, though, and is not an option in practice.
In a follow-up paper to Szegedy et al. (2014), Goodfellow et al. (2015)3 provide a fast method to generate adversarial examples. Instead of searching the entire neighborhood of a given data point, they directly move in the direction of the gradient of the loss function (with respect to the input) used to train the model. Following the direction of the gradient is moving in the exact opposite way that Stochastic Gradient Descent does during optimization. While this method is auspicious for attackers trying to break neural systems, it also offers a simple way to make models more robust, by injecting the generated adversarial examples during training. Miyato et al. (2016)4 further improve on this idea by computing an adversarial direction without looking at label information. Regarding only the model distribution, they make this approach applicable also to semi-supervised learning, and call their method Virtual Adversarial Training. They improved the state-of-the-art of the semi-supervised image classification tasks on the SVHN5 and CIFAR-106 data sets, two popular ways two asses machine learning performance in vision. Using adversarial examples when training a network can thus be seen as yet another form of regularization: Beyond making models more robust to adversarial attacks, it can also yield improvements on test distributions that do not contain adversarial examples.
Generating adversarial examples, however, is not readily transferable to NLP tasks for mainly two reasons. First of all, while model failure is self-explanatory in classification tasks, more complex evaluation metrics need to be considered for structured prediction like sequence labeling or language generation. Secondly, and more importantly, model input is usually made of words (sometimes characters), which by their very nature form a discrete space. It is not obvious how some layer of small adversarial perturbations can be added to the input data. Such changes would certainly not be imperceptible, at least not on surface form. One notable exception is Automatic Speech Recognition and Translation, where input is not discrete. Qin et al. (2019)7 and Iter et al. (2019)8 recently demonstrated how imperceptible modifications to sound waves can effect almost arbitrary model output, corroborating the insights from vision. Exploiting the fact that written words are often mapped into a continuous space via embeddings, Miyato et al. (2017)9 make adversarial and virtual adversarial training applicable to text by adversarially perturbing the embeddings. They achieve improvements on various text classification tasks and learn higher-quality word embeddings. Adversarially perturbed embeddings are also successfully used by Wu et al. (2017)10 for relation classification. This method makes models more robust, but doesn’t generate any adversaries because perturbed embeddings do not translate to any real words.
Adversarial examples in NLP
Does this mean we can settle to adding noise to word embeddings or hidden states to make a model more robust, and not worry about adversarial input? Are neural NLP systems working on written text immune to adversarial attacks? Well, things happen to be even worse. It is possible to make visible changes to the input that preserve meaning but nevertheless cause the model to predict differently:
- Jia and Liang (2017)11 fool reading comprehension models by inserting sentences to the Stanford Question Answering Dataset (SQuAD) that add to the text without altering the information for which is asked.
- Glockner et al. (2018)12 replace single words in the SNLI test set with synonyms or antonyms, which results in a significant drop in model performance compared to the original test set.
- Belinkov and Bisk (2018)13 break character-based machine translation by introducing noise such as misspellings or character swaps that pose no challenge to humans.
- Building on Miyato et al. (2017)9, Sato et al. (2018)14 perturb embeddings in the direction of existing word embeddings, and weight those directions with gradient information. This subtle modification permits the easy reconstruction of real words that are likely to deceive the model.
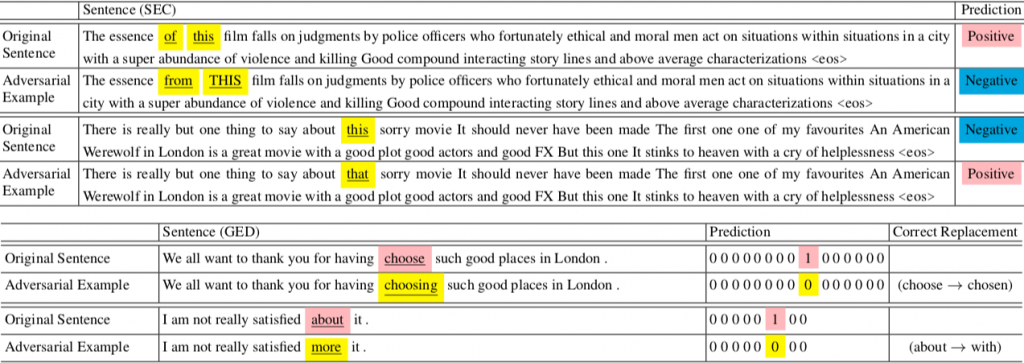
Can adversarial training help in such cases?
- Wang and Bansal (2018)16 follow up on the findings from Jia and Liang (2017)11 and show that adversarial training results in models that are more robust to adversarial attacks, provided that there is sufficient variance within the adversaries used during training.
- Iyyer et al. (2018)17 use paraphrases to create adversarial examples and manage to break sentiment analysis as well as textual entailment models. When they include adversaries in the training set, the models behave more robustly on development sets analogously enriched with adversaries.
- Minervini and Riedel (2018)18 use external knowledge and first-order logic to construct adversarial examples for Natural Language Inference tasks. Training on adversarilly augmented data makes the models slightly more robust on the regular test sets and drastically improves performance on adversarial data.
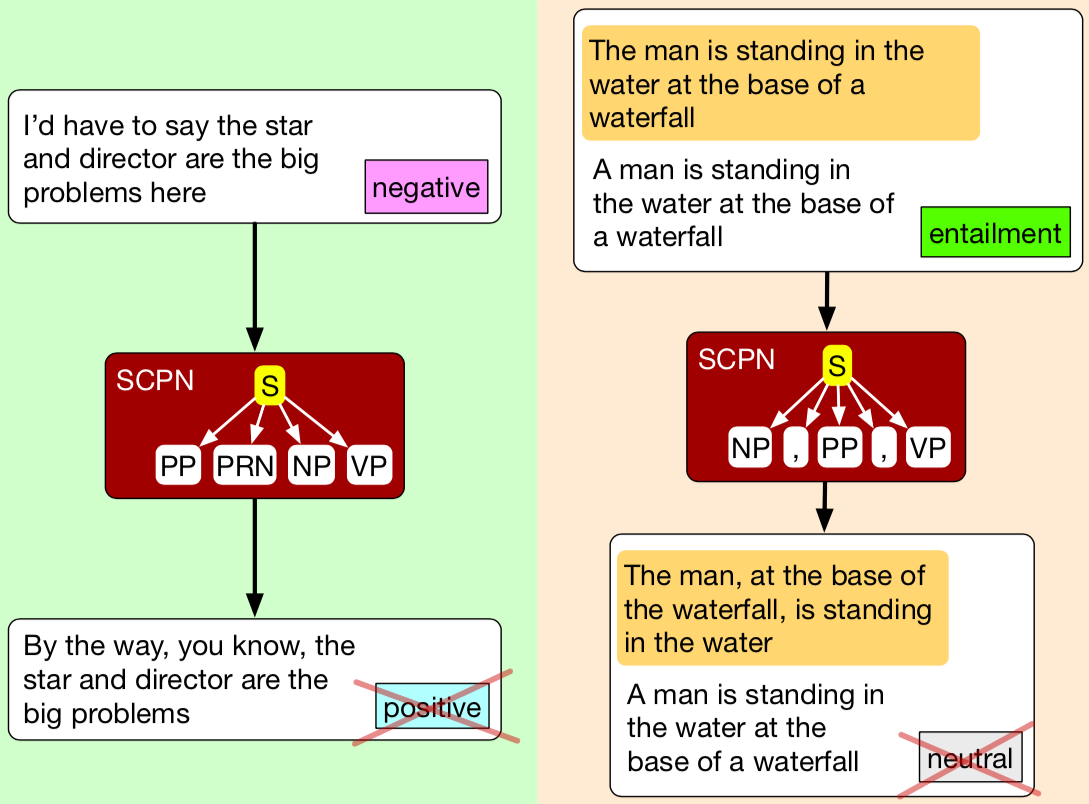
The mentioned papers show various ways for generating adversarial examples for NLP tasks, e.g. by adding
uninformative sentences, using paraphrases, or by synthesizing data that is known to violate certain conditions.
Human evaluation is sometimes needed to evaluate the quality of the generated adversaries with respect to a chosen
metric (e.g. semantic similarity, or how “natural” they appear to humans). Black box approaches use heuristics and
algorithms that do not depend on the internal properties of the model at hand. If the model is accessible and
differentiable, gradient information could be used to look for adversarial data (white box approach).
Several experiments have shown that feeding adversarial data into models during training increases robustness to
adversarial attacks. Even so, more research needs to be carried out to investigate to what extent this type of
adversarial training for NLP tasks can help models generalize to real world data that hasn’t been crafted in an
adversarial fashion.
2 The (adversarial) game is on!
A conceptually different training method, also called adversarial, does not employ adversarial examples at all. Here, adversarial refers to the fact that different parts of the model pursue adverse objectives, effectively playing an adversarial game. This approach has first been used by Goodfellow et al. (2014)19 in a generative setting, where one neural network is trying to estimate some data distribution while another one is trying to discriminate between real and generated data. While playing this adversarial game, both sides improve their performance using the discriminator’s judgement as a training signal until a saturated state is reached. This is also called min-max optimization because one network is trying to maximize the other network’s loss and vice-versa. Unlike generating adversarial examples for training, adversarial min-max optimization can be readily incorporated into many and diverse NLP tasks:
Li et al. (2017)20 apply the original generative approach to dialogue generation for making machine output resemble human-generated data. Alternatively, it is possible to further build on the min-max optimization architecture in order to extract domain-invariant features from the input. This very popular approach has been successfully applied to many discriminative settings. Here we usually aim at predicting some label (or otherwise accomplish whatever goal there is) given some feature representation/hidden state that is computed by the first layers of the network. Now, another branch of the model simultaneously tries to classify the domain of the input based on the same features/hidden states. The bottom part of the networks adversarilly tries to maximize the domain classifier’s loss – while both parts learn through backpropagation.
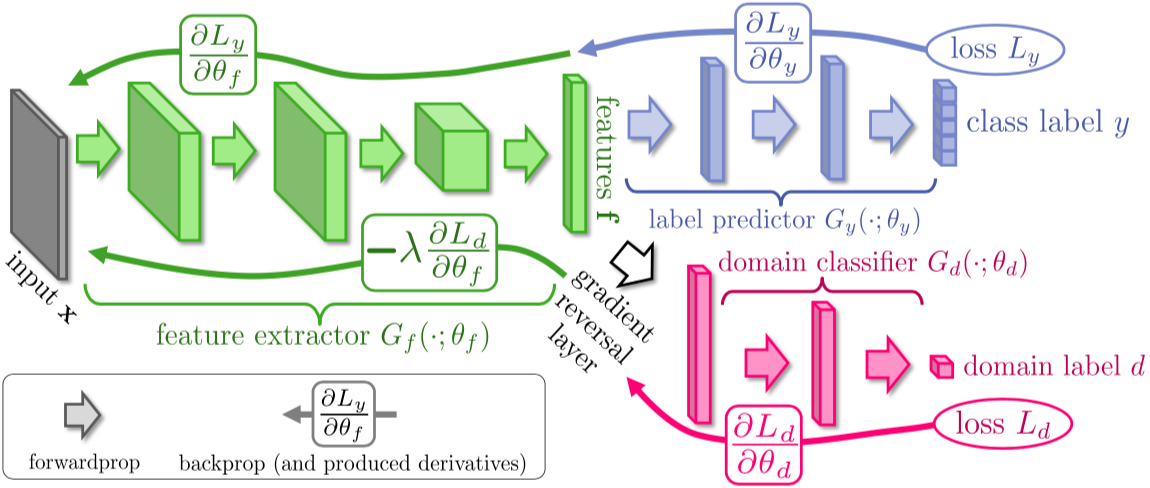
The same principle can be applied to shared-private models, where both domain-dependent features (the private part) and domain-independent features (the shared part) are extracted and processed in parallel. Here the adversarial game between domain classifier and feature generator ensures that the shared feature space does not contain domain-specific elements, whereas the private spaces can still store information specific to each domain.
While adversarial min-max-optimization is most often performed in a binary set up where the classifier aims to distinguish between two distributions, it can be generalized to a setting with multiple types of input. Chen and Cardie (2018)22 present Multinomial Adversarial Networks for multi-domain text classification (MDTC) that seek to minimize divergences between the feature representations of multiple domains.
Computing hidden states that capture invariances across data shifts is desirable for many NLP tasks. Therefore, adversarial feature extraction is not restricted to cross-domain learning:
- Liu et al. (2017)23 and later Marasović and Frank (2108)24 combine it with Multi Task Learning. Instead of extracting features that are domain-invariant, they make the shared space of an MTL shared-private model task-invariant.
- Kim et al. (2017)25 extract domain-invariant features to bridge the data shift from synthetic to user data and from dated to current data.
- Joty et al. (2017)26 enable unlabeled similarity rankings for community question answering to learn from labeled data in foreign languages by extracting language-invariant features.
- Similarly, Zhang et al. (2017)27 map word embeddings from one language to another without using cross-language information.
- Qin et al. (2017)28 improve performance on implicit discourse relation classification tasks by harvesting data that includes explicit connectives and adversarially extracting features that disregard the discourse marker.
As the works listed above show, min-max optimization is useful in many NLP tasks, and was shown to improve on previous benchmarks in a wide area of applications. It can easily be integrated into existing systems and should be considered whenever there is a need to integrate one data distribution with another and to prevent learning biases and signals particular to one of the distributions.
3 Two methods combined
The two types to adversarial training that I have described are independent concepts and should not be confounded. The reason for calling them both adversarial is not coincidental, though. Both methods pursue adversarial objectives in some sense, and exploit this adversarial pursuit to improve system performance. The following table juxtaposes the key differences:
| Using Adversarial Examples in Training | Min-Max-Optimization | |
|---|---|---|
| Setting | Single Task (*) | Joint Learning |
| Goal | Improve robustness, defend against adversarial attacks | Estimate a distribution (e.g. robust features, or real data) |
| Adversarial Players | Model vs. adversarial examples | (Data or feature) generator vs. discriminator (auxiliary task) |
| Learning | Model is updated via backpropagation (**) | Generator AND discriminator are updated via backpropagation |
| Main challenge | Create adversarial examples that (i) are similar to existing training samples and (ii) resemble human data | Align two disparate distributions (fake/real data, or distinct domains) |
(*)/(**) More complex approaches also update the generation of adversaries. In this case, the model and the generation of adversarial examples can be learned jointly.
Because they are independent of each other, both methods can be used in parallel to serve their respective purposes.
Moreover, it is even possible to integrate them. Kang et al. (2018)29
demonstrate this for textual entailment. In a first step, they transform single sentences from the training data
using external knowledge databases (paraphrases, hypernym/antonym relations etc.). Combining original and
transformed sentences with logical rules, they create new entailment triples (premise, hypothesis, entailment
label). Many of these new data points prove to be adversarial, fooling systems trained on data containing the
original sentences. This is a black box approach for generating adversarial examples that uses heuristic rules. In a
second step, they use a sequence-to-sequence model to generate new data. After some conventional pretraining on the
entailment triples from the training data, each batch of newly generated data points is labeled by the textual
entailment model. The entailment loss is backpropagated to improve the entailment model, and the reverted loss
updates the seq2seq model so as to generate examples that are even more challenging for the entailment model.
Essentially, this second method is a white box approach that generates adversarial examples through
adversarial min-max optimization, where the entailment model is the discriminator and the
sequence-to-sequence model is the competing generator.
Adversarial min-max optimization can be used to generate adversarial examples even when model parameters are
not accessible. To this end, Zhao et al. (2018)30
couple auto-encoders with generative adversarial networks similar to the ones introduced by Goodfellow et al.
(2014). As is standard for auto-encoders, discrete text is encoded into continuous space, decoded back into input
space, and the model is trained to minimize the reconstruction loss. On top of that, a generator is trained to
encode random noise, and a discriminator is trained to discern between noise encodings and real data encodings. The
training of encoder, generator and discriminator is done in an adversarial (min-max) fashion. After training is
completed, an inverter is trained to transform encodings into the “noise space”.

Provided that the generator has been trained well enough, it is now possible to generate discrete adversarial examples that resemble human-generated input. Note that the original search problem remains: Scanning a continuous subspace for points which fool the main task. As in vision, various search algorithms can be used but will not be discussed here. There are some important benefits of this approach over methods that rely on heuristic rules to transform the input data: Not only is it possible to search for minimal perturbations that break system performance. If these perturbations can be transformed into meaningful, human-like data, researchers are able to analyze what types of changes the system is particularly susceptible to, e.g. find the grammatical or morphological categories where alterations will have the biggest impact.
What to take home from this
Once we see the differences and similarities between training with adversarial examples and min-max-optimization clearly, we also understand how they can be applied in combination, in cases where both options can be pursued. This can be particularly useful when trying to estimate natural adversarial examples that resemble human data. So far, many adversarial examples in NLP manage to fool models but differ from real word data to various degrees. Even so, they can help regularize a model and improve robustness, and they are extremely useful in helping researchers to better understand how neural models behave.
- Szegedy et al. (2014) Intriguing properties of neural networks, https://arxiv.org/abs/1312.6199
- See Goodfellow et al. (2015), Liu et al. (2017), Minervini and Riedel (2018) for transferal of adversarial examples
- Goodfellow et al. (2015) Explaining and Harnessing Adversarial Examples, https://arxiv.org/abs/1412.6572
- Miyato et al. (2016) Distributional Smoothing with Virtual Adversarial Training, https://arxiv.org/abs/1507.00677
- Netzer et al. (2011) Reading Digits in Natural Images with Unsupervised Feature Learning, http://ufldl.stanford.edu/housenumbers/
- Krizhevsky (2009) Learning Multiple Layers of Features from Tiny Images, https://www.cs.toronto.edu/~kriz/cifar.html
- Qin et al. (2019) Imperceptible, Robust, and targeted Adversarial Examples for Automatic Speech Recognition, https://arxiv.org/abs/1903.10346
- Iter et al. (2019), Generating Adversarial Examples for Speech Recognition, http://web.stanford.edu/class/cs224s/reports/Dan_Iter.pdf
- Miyato et al. (2017) Adversarial Training Methods for Semi-Supervised Text Classifications, https://arxiv.org/abs/1605.07725
- Wu et al. (2017) Adversarial Training for Relation Extraction, https://www.aclweb.org/anthology/D17-1187
- Jia and Liang (2017) Adversarial Examples for Evaluating Reading Comprehension Systems, https://arxiv.org/abs/1707.07328
- Glockner et al. (2018) Breaking NLI Systems with Sentences that Require Simple Lexical Inferences, https://arxiv.org/abs/1805.02266
- Belinkov and Bisk (2018) Synthetic and Natural Noise Both Break Neural Machine Translation, https://arxiv.org/abs/1711.02173
- Sato et al. (2018) Interpretable Adversarial Perturbation in Input Embedding Space for Text, https://arxiv.org/abs/1805.02917
- Sato et al. (2018) Interpretable Adversarial Perturbation in Input Embedding Space for Text, https://arxiv.org/abs/1805.02917
- Wang and Bansal (2018) Robust Machine Comprehension Models via Adversarial Training, https://arxiv.org/abs/1804.06473
- Iyyer et al. (2018) Adversarial Example Generation with Syntactically Controlled Paraphrase Networks, https://arxiv.org/abs/1804.06059
- Minervini and Riedel (2018) Adversarially Regularising Neural NLI Models to Integrate Logical Background Knowledge, https://arxiv.org/abs/1808.08609
- Goodfellow et al. (2014) Generative Adversarial Nets, https://arxiv.org/abs/1406.2661
- Li et al. (2017) Adversarial Learning for Neural Dialogue Generation, https://arxiv.org/abs/1701.06547
- Ganin and Lempitsky (2017), Unsupervised Domain Adaptation by Backpropagation, https://arxiv.org/pdf/1409.7495.pdf
- Chen and Cardie (2018) Multinomial Adversarial Networks for Multi-Domain Text Classification, https://arxiv.org/abs/1802.05694
- Liu et al. (2017) Adversarial Multi-task Learning for Text Classification, https://arxiv.org/abs/1704.05742
- Marasović and Frank (2108) SRL4ORL: Improving Opinion Role Labeling Using Multi-Task Learning With Semantic Role Labeling, https://arxiv.org/abs/1711.00768
- Kim et al. (2017) Adversarial Adaptation of Synthetic or Stale Data, https://www.aclweb.org/anthology/P17-1119
- Joty et al. (2017) Cross-language Learning with Adversarial Neural Networks: Application to Community Question Answering, https://arxiv.org/abs/1706.06749
- Zhang et al. (2017) Adversarial Training for Unsupervised Bilingual Lexicon Induction, https://www.aclweb.org/anthology/P17-1179
- Qin et al. (2017) Adversarial Connective-exploiting Networks for Implicit Discourse Relation Classification, https://arxiv.org/abs/1704.00217
- Kang et al. (2018) AdvEntuRe: Adversarial Training for Textual Entailment with Knowledge-Guided Examples, https://arxiv.org/abs/1805.04680
- Zhao et al. (2018) Generating Natural Adversarial Examples, https://arxiv.org/abs/1710.11342



