We are happy to announce six new publications, with partners and colleagues, to be presented at ACL 2023, Findings of ACL 2023 and SemEval 2023 in Toronto in July. Looking forward to the conference and discussing our work!
-
MM-SHAP: A Performance-agnostic Metric for Measuring Multimodal
Contributions in Vision and Language Models & Tasks,
by Letitia Parcalabescu and Anette Frank, to appear in ACL 2023
We present MM-SHAP to quantify at dataset, instance and token-level how much individual modalities contribute for the prediction in multimodal tasks. We found that models suffer from unimodal collapse to different extents and different directions (exacerbated visual or text focus).
-
Similarity-weighted Construction of Contextualized Commonsense
Knowledge Graphs for Knowledge-intense Argumentation Tasks,
by Moritz Plenz, Juri Opitz, Philipp Heinisch, Philipp Cimiano and Anette Frank, to appear in ACL
2023
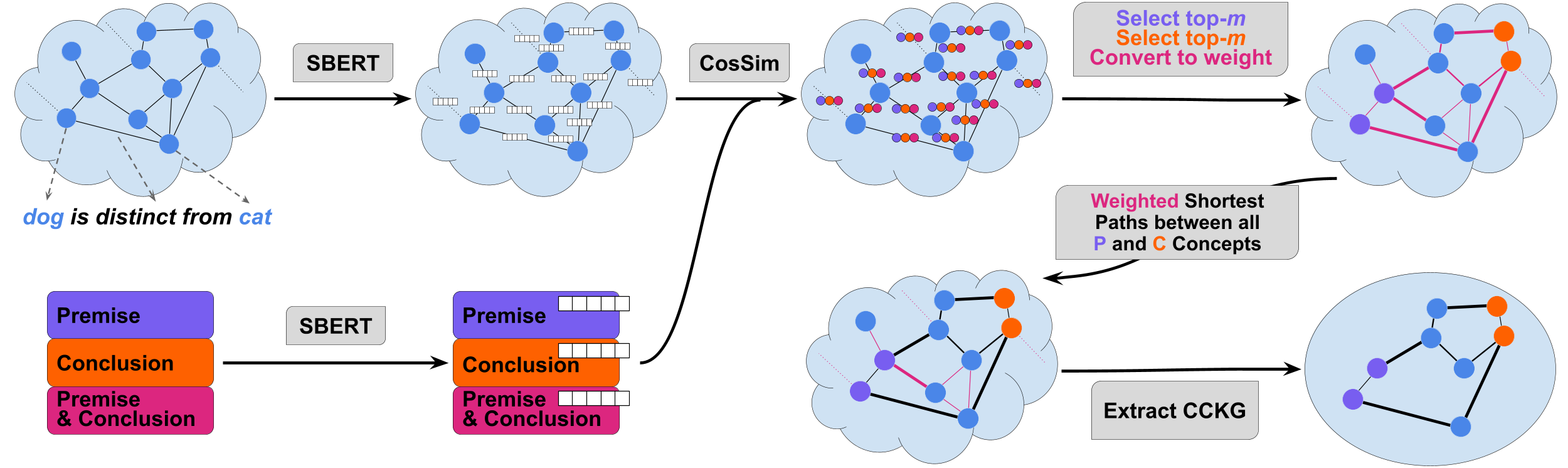
We present a method to construct Contextualized Commonsense Knowledge Graphs (CCKGs). The method goes beyond context-insensitive knowledge extraction heuristics by computing semantic similarity between KG triplets and textual arguments to extract contextualized knowledge paths that connect a conclusion to its premise, while maximizing similarity to the argument.
-
Exploring Large Language Models for Classical
Philology
by Frederick Riemenschneider and Anette Frank, to appear in ACL 2023This work is the first to systematically develop pre-trained language models for Classical Philology. We gather a large-scale Ancient Greek pre-training corpus and train a range of encoder-only and encoder-decoder language models from scratch for Ancient Greek and Latin. Our models achieve state-of-the-art results in PoS tagging, dependency parsing, and lemmatization. Additionally, we evaluate our models on semantic and knowledge probing tasks. - With a Little Push, NLI Models can Robustly and Efficiently Predict Faithfulness
by Julius Steen, Juri Opitz, Anette Frank and Katja Markert, to appear in ACL 2023This work shows that faithfulness of generated text can be robustly and efficiently predicted with NLI models, by using three simple strategies: 1. data augmentation with a handful of templates for NLI-to-faithfulness domain adaption 2. Monte-Carlo Inference 3. Subtraction of NLI contradiction score from NLI entailment score. - SETI: Systematicity Evaluation of Textual Inference
by Xiyan Fu and Anette Frank, to appear in Findings of ACL 2023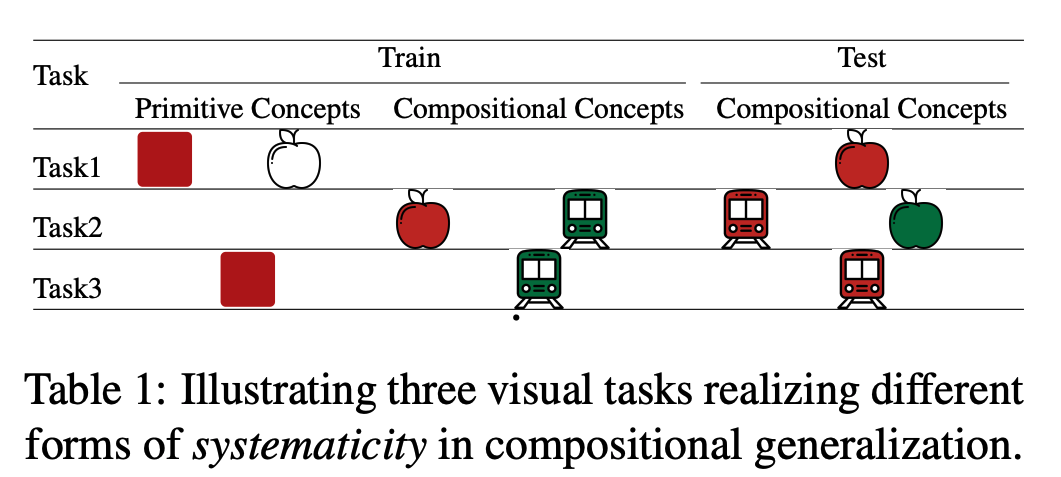
We propose SETI, the first comprehensive benchmark for evaluating the systematicity capabilities of PLMs when performing NLI. Experiments show that PLMs can distinguish novel compositions with known primitives and composing knowledge with high accuracy, but are limited when lacking such knowledge. We also find that PLMs can improve in performance drastically once they are exposed to crucial compositional knowledge in minimalistic shots.
- ACCEPT at SemEval-2023 Task 3: An Ensemble-based Approach to Multilingual Framing
Detection
by Philipp Heinisch, Moritz Plenz, Anette Frank and Philipp Cimiano, to appear in SemEval 2023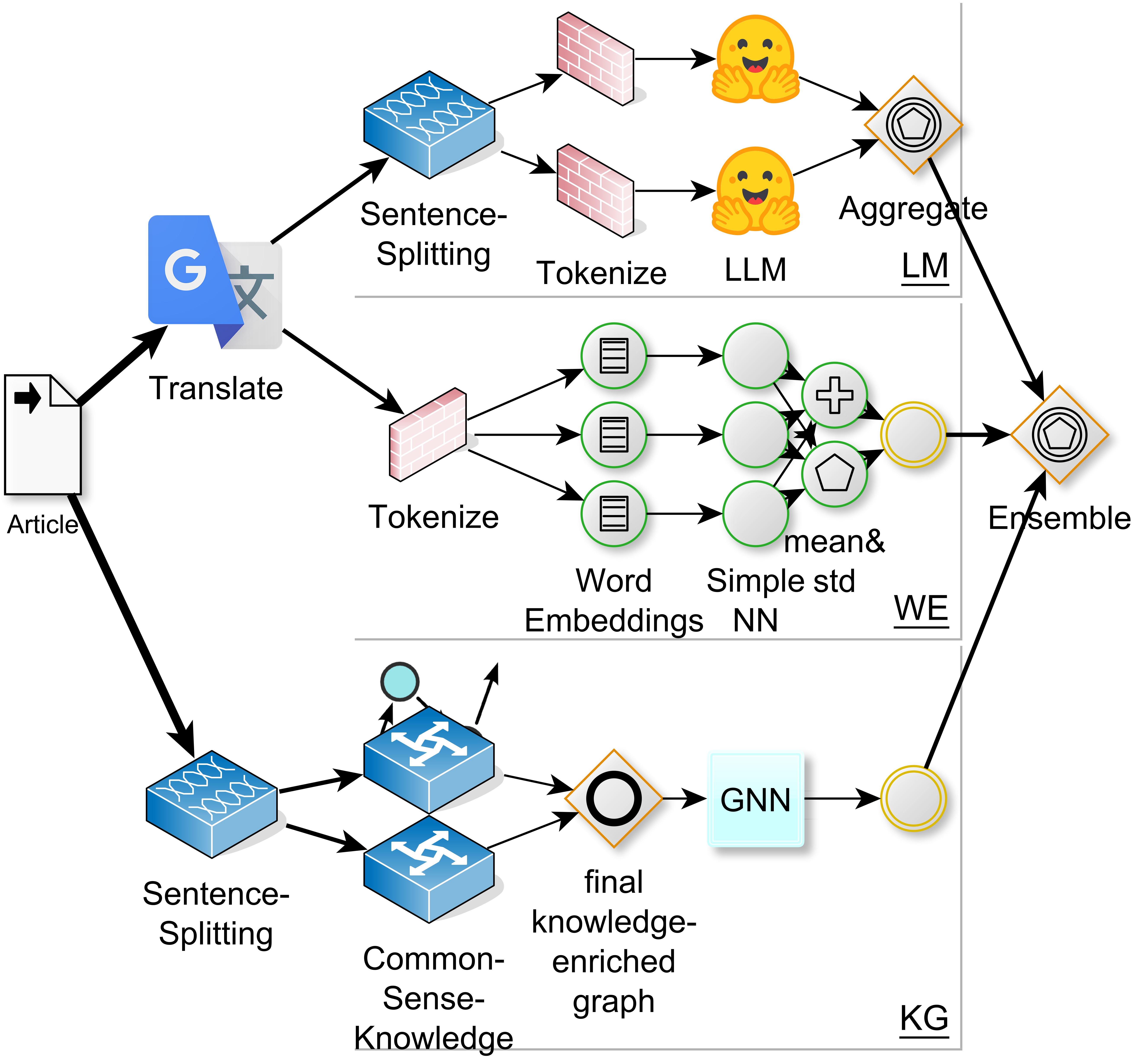
Predicting the generic frame set from a lengthy (multilingual) news article poses a significant challenge. However, by employing an ensemble of a Graph Neural Networks (GNNs) that process background-knowledge enriched graphs, along with simple neural networks utilizing static word embeddings (which exhibit surprisingly strong performance), we can achieve consistent and reliable results.
Congratulations to all authors!



