How do multilingual language models develop their ability to transfer knowledge across languages? In our ACL paper, we take a look inside these models during pre-training to uncover the mechanisms behind cross-lingual generalization—and find intriguing patterns that appear to be linked to compression.
📜 Cross-Lingual Generalization and Compression: From Language-Specific to Shared Neurons
Here's something puzzling: when we train a simple classifier to identify the source language from a model's hidden representations, early checkpoints solve this task almost perfectly. But as training progresses, performance mysteriously drops in certain layers. It is as if the model gradually "forgets" language-specific features in these layers—or rather, repurposes them for something more important.
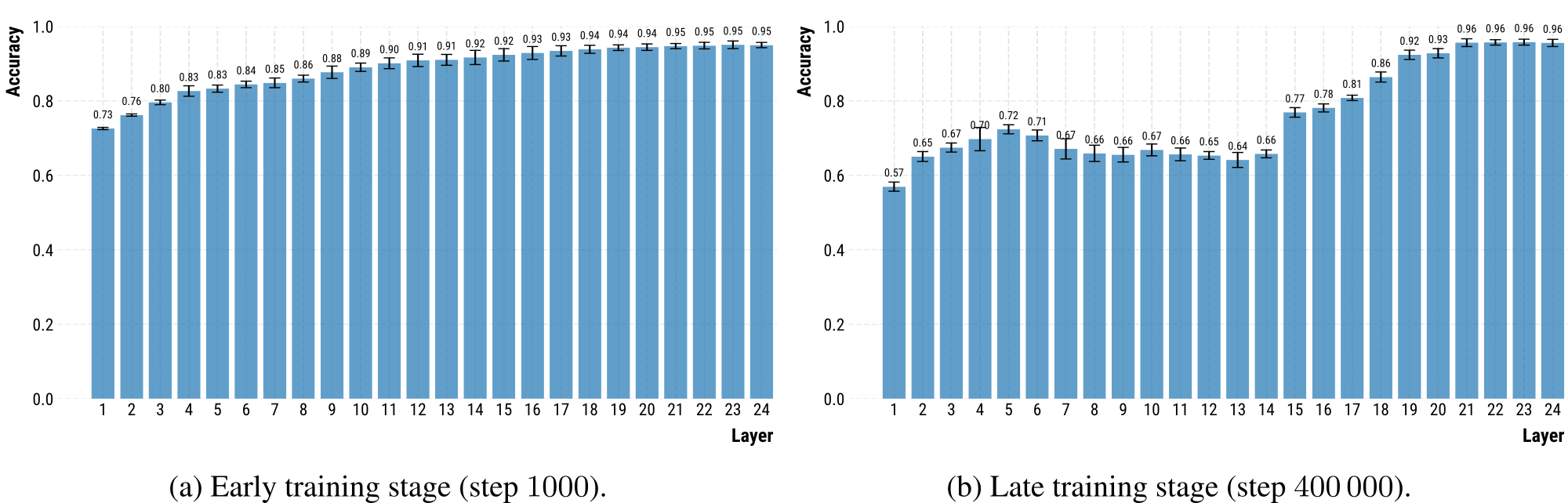
We tracked how specific concepts (like "earthquake" or "joy") evolve across languages during pre-training. What we discovered was fascinating: models progressively align these concepts across languages, developing "cross-lingual expert neurons"—particularly in the middle layers. These neurons encode generalized concepts independent of language, allowing the model to represent the same idea more efficiently across multiple languages.
The practical implications are striking. Consider BLOOM-560m at checkpoint 10,000: when we activate "earthquake" neurons derived from Spanish data and let the model generate freely, it produces Spanish text about earthquakes—exactly what you'd expect.
But here is where it gets interesting: at checkpoint 400,000, after cross-lingual generalization has occurred, activating those same Spanish-derived earthquake neurons causes the model to generate English text about earthquakes—without any prompting to switch languages!
This work reveals how multilingual models evolve from maintaining separate representations for each language to developing shared representations that transcend linguistic boundaries.



