As premodern texts are passed down over centuries, errors inevitably accumulate. These errors can be challenging to identify precisely because the most elusive ones have survived undetected for so long. So how can this challenge be tackled with modern computational methods?
📜 An Annotated Dataset of Errors in Premodern Greek and Baselines for Detecting Them
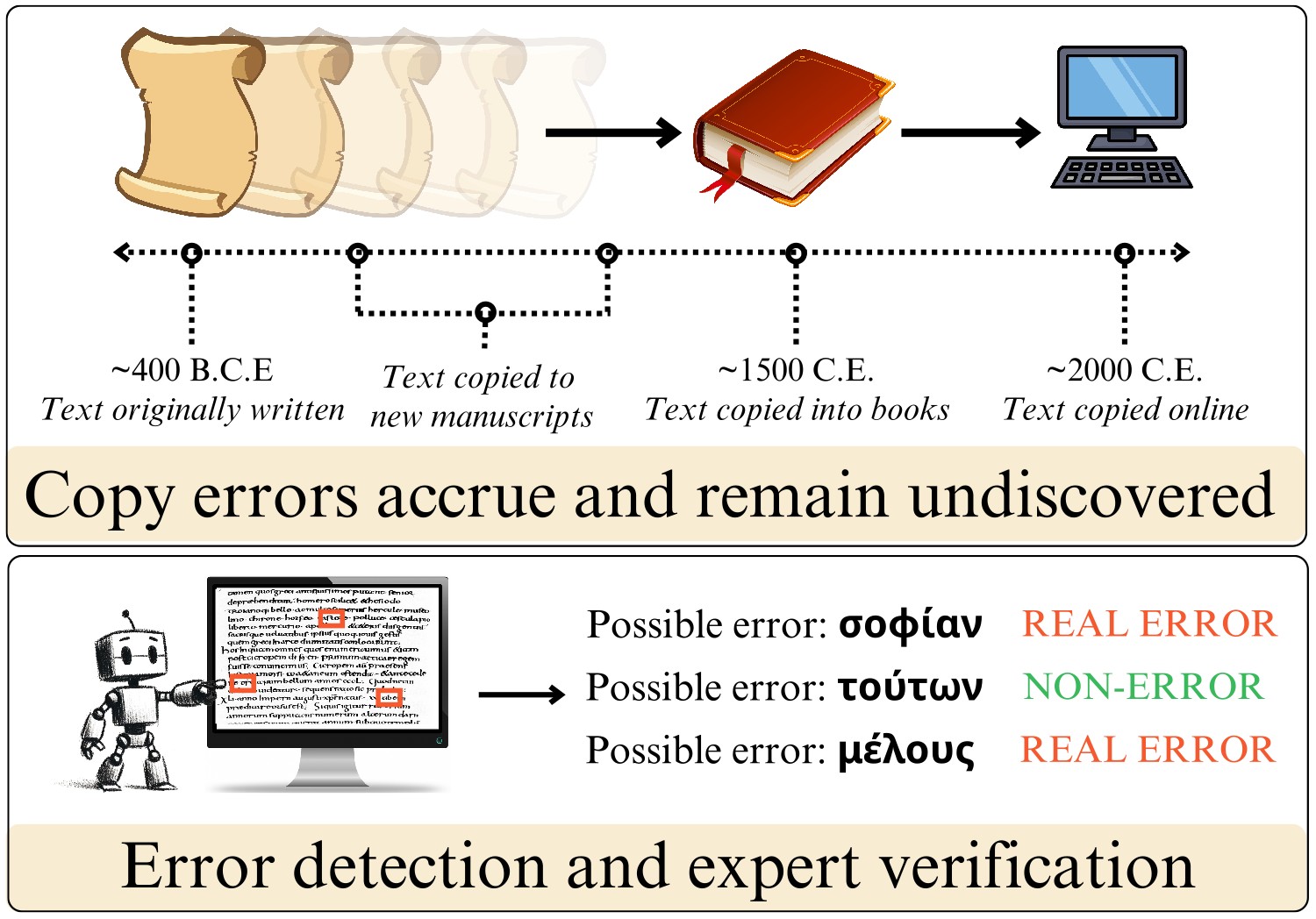
While prior work has mainly evaluated error detection methods using artificially-generated errors, this paper introduces the first dataset of real errors in premodern Greek texts. The research team tested various methods including LLMs and found that discriminator-based models significantly outperform other approaches, while GPT-4 surprisingly cannot solve this specialized task effectively.
Congratulations to the authors Creston Brooks, Johannes Haubold, Charlie Cowen-Breen, Jay White, Desmond DeVaul, Frederick Riemenschneider, Karthik Narasimhan and Barbara Graziosi.



