This blog post aims to give a broad overview over the development of Commonsense Reasoning (CR) in the field of Natural Language Processing (NLP) and its multimodal intersection with Computer Vision (CV). What makes CR so important in the age of Deep Learning, how did the approaches to it and datasets for it change over time, what are the main challenges, how can other modalities than language contribute towards CR in Machine Learning and why is Commonsense Reasoning still a hot topic?
What is Commonsense Reasoning?
Commonsense Reasoning requires a machine to reason based on ‘knowledge about the everyday world’1
. This knowledge is assumed to be widely known by humans and so they most of the time omit any mention of it from
text, visuals or other modalities.2
Examples
for commonsense knowledge are abundant: A lemon is sour, in a waterfall, water flows downwards due to gravity, if
you see a red traffic light, you are supposed to slow down and stop and you typically don’t make a salad out of a
polyester shirt3
. Since all that knowledge is obvious for humans and thus rarely explicitly mentioned, it is hard to acquire for a
machine, let alone reason with it.
This reasoning abilty based on commonsense knowledge is key to really understand a text and answer comprehension questions about it. CR is thus closely related to Reading Comprehension, Question Answering and Natural Language Understanding in general.
To perform Commonsense Reasoning, one has to consider facts about time, space, physics, biology, psychology, social interactions and many more.1 3 4
Why Commonsense Reasoning?
But why is Commonsense Reasoning a thing, anyway?
The question what makes a machine intelligent goes all the way
back to 1950 when Alan Turing invented his famous Turing Test. In fact, Commonsense knowledge and reasoning is
considered a vital part of machine intelligence5
and for machines to achieve human-level performance in various tasks, commonsense knowledge will most certainly be
necessary3
.
The importance of real-world knowledge for NLP was first discussed in 1960 in the context of machine
translation. 3
6
Since then there have been various approaches to the task of Commonsense Reasoning and to handling and acquiring
commonsense knowledge, ranging from logic-based approaches over building handcrafted7
8
or crowd-sourced1
knowledge bases and web mining to more recent neural methods.3
9
How to test for commonsense?
Alongside the methods to tackle the problem there has always been the question of how to correctly evaluate Commonsense Reasoning. Over the years, several datasets have been developed for that purpose.
Winograd Schema Challenge
You most certainly have heard of the so called ‘Winograd schemas’10 . They have been developed by Levesque et al. in 2012 as an alternative to the Turing Test and are named after Terry Winograd (1972), who was the first to introduce them:
The city councilmen refused the demonstrators a permit because they [feared/advocated] violence.
A Winograd schema consists of a sentence, a binary question and two possible answers. Every schema involves two parties, a pronoun or possessive adjective in possible reference to both of the parties and the possible answers, which can be any of the two parties:
The trophy doesn’t fit in the brown suitcase because it’s too big.
What is too big?
Answer 0: the trophy
Answer 1: the suitcase
Key to a schema is the so called ‘special word’, that appears in the sentence and possibly the question. If replaced
with its ‘alternate word’, the answer to the question changes. In the above example this special word is ‘big’. If
we replace ‘big’ with ‘small’, the answer to the question changes from ‘the trophy’ to ‘the suitcase’.
Because of
this special property, the schemas were said to be impervious to ‘tricks involving word order or other features of
words or groups of words’10
.
Kocijan et al. (2020)9 provides a comprehensive overview over all variations of the Winograd schema dataset and over a broad range of approaches tackling the WSC, ranging from feature-based methods [1] (which are the oldest and still present), to neural ones without pre-trained language models [2] (2017 and 2018 mostly) and with the use of large-scale pre-trained language models [3] (starting in 2018 and still ongoing). An overview regarding the different performances of some of those models is provided in the table below. All results are achieved on a basic version of the Winograd dataset (WSC273) and values are taken from Kocijan et al. (2020) unless stated otherwise.
| Model | Accuracy (%) |
| Humans (Sakaguchi et al. (2019)) | 96.5 |
| Sakaguchi et al. (2019) [3] | 90.1 |
| Wang et al. (2019) [2] (unsupervised) | 62.4 |
| Liu et al. (2017) [2] (supervised) | 52.8 |
| Emami et al. (2018) [1] | 57.1 |
| Random guess | 50.0 |
We can see that all approaches not using large pre-trained language models are far away from reaching human
performance and closer to a random guess baseline. Unsupervised approaches using neural models [2] beat supervised
approaches of the same category but are still far from perfect.
Neural approaches using pre-trained language
models [3] though are really close to human performance with the best performing approach shown in the table
(Sakaguchi et al. 2019).
However, systems that have succeeded on WSC273, didn’t show the ability to solve other
Natural Language Understanding tasks like Commonsense Reasoning.9
They even aren’t able to answer simple questions about narrative text11,
thus relativizing the high performance of language model approaches and the usefullness of the Winograd schemas as a
benchmark for machine intelligence or a machine’s ability to perform Commonsense Reasoning.
Luckily, over the years several other benchmarks to test CR have been developed. Most of these are in fact crowd-sourced, which is reasonable given that Commonsense Knowledge is something inherently known by humans.
Other benchmarks
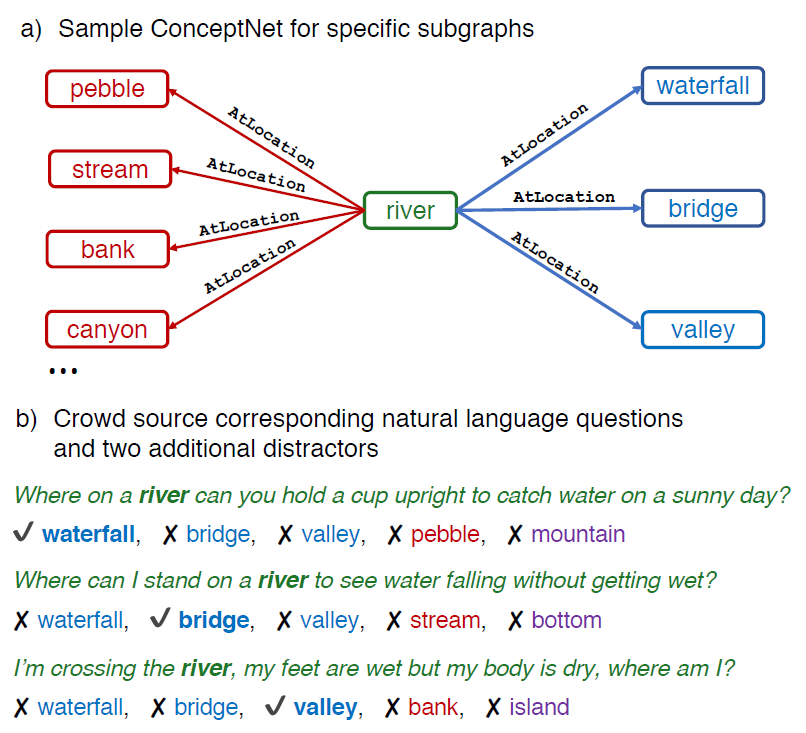
Not a benchmark itself, but a resource several datasets or approaches are built upon, there’s ConceptNet1
.
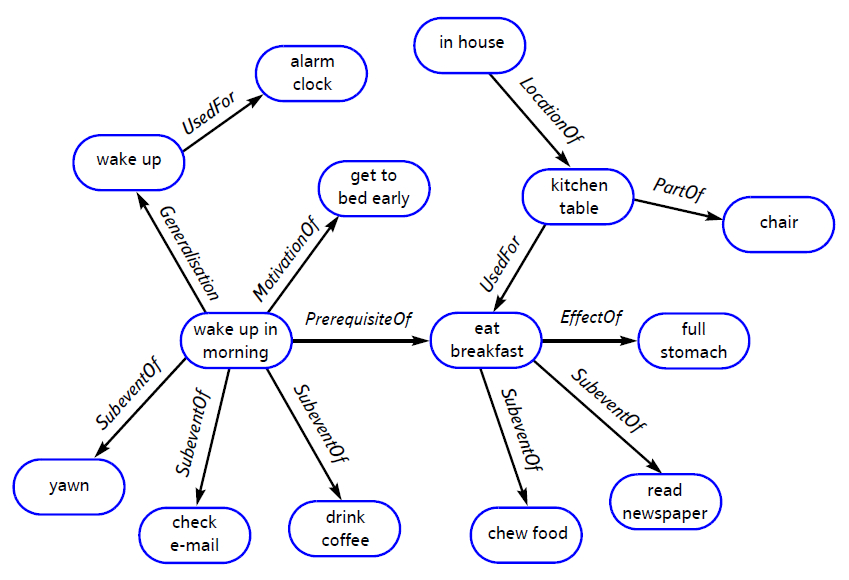
ConceptNet (2004) consists of a wide range of (commonsense) concepts and their relations as
illustrated below:
Story Cloze Test/ROC Stories (2016)12 : Based on a four-sentence context a system has to choose between a right and a wrong ending.

SWAG (2018)13 : A multiple choice Question Answering dataset, derived from video captions. The goal is to predict which event is most likely to happen next. Also proposing a new method to construct a non-biased dataset (‘Adverarial Filtering’).

CommonsenseQA (2019)14 : Built upon ConceptNet a system has to answer a question that includes a specific source concept by choosing from five possible answers. There’s also a very competetive leaderboard for the dataset.
DROP (2019)15 is a Reading Comprehension benchmark that requires Discrete Reasoning Over Paragraphs. Based on a paragraph, a system has to answer a question that requires a comprehensive understanding of the paragraph. Types of reasoning include: subtraction, comparison, selection, addition, count and sort, coreference resolution, other arithmetics, set of spans and other.

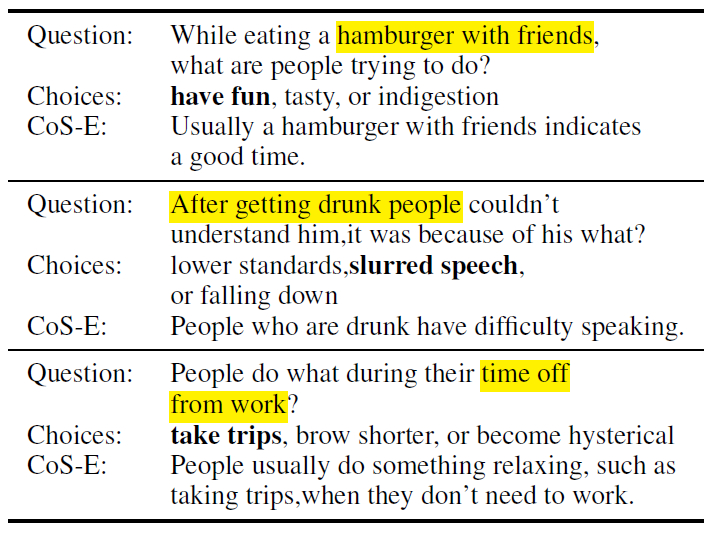
Explain Yourself!/CoS-E (2019)16 : Provided with a question, three choices and an explanation from the Common Sense Explanations (CoS-E) dataset, a system has to generate a valid explanation instead of chosing from the provided possible answers.
CODAH (2019)17 : This datasets consists of prompts, subjects and candidate completions collected specifically to target weaknesses of state-of-the-art neural question answering systems. Tested categories include idioms, negation, polysemy, reference and quantitative reasoning. This dataset is a more difficult extension to SWAG (Zellers et al. 2018a)13 .
Example (taken from Chen et al. (2019)17
):
A man on his first date wanted to break the ice. He
- drank all of his water.
- threw the ice at the wall.
- looked at the menu.
- made a corny joke.
Event2Mind (2019)18 : A system is provided with an event (‘X drinks coffee in the morning’) and has to reason about the likely intents (‘X wants to stay awake’) and reactions (‘X feels alert’) of anyone who participates in the event.
Social IQA (2019)19 : The first large-scale benchmark for commonsense reasoning about social situations. Based on a given context, a system has to answer a multiple choice question.

However, there are still more datasets available than mentioned here. Now we will take a closer look at the results that models have achieved on those benchmarks, why they might be problematic and why it is good to have several different tests for Commonsense Reasoning.
Recent approaches to CR and their problems
With the advent of the Transformer20 and the two most famous models built upon it, namely OpenAI’s GPT-121 and BERT22 , NLP as a whole experienced some drastic improvements. The area of Commonsense Reasoning also hasn’t been spared by those changes.
Up to 2018 the neural approaches in the field were trained mostly from scratch and still struggled heavily when attempting to perform Commonsense Reasoning.9 In 2018 the Transformer found it’s way into the field. Researchers started using huge pre-trained language models like BERT either with or without fine-tuning on their specific Commonsense Reasoning task and applied them to the available benchmarks – with huge success.
In fact, those models even outperformed humans on several tasks – a sign that there’s almost certainly something
wrong. After all, our models are supposed to ‘think’ like humans or at least act like they would.
On critical
examination it was soon obvious that the models didn’t really learn anything regarding commonsense. They didn’t
perform well on other more sophisticated CR tasks, while having achieved high performance in tasks that were said to
be good benchmarks for Commonsense Reasoning. The language models merely memorize and approximate world
knowledge23
and don’t have a deep understanding of it yet.
An example of such a problematic case is shown in the table below.
| Model | Dataset | Accuracy (%) |
| Human experts (Zellers et al. 2018a) | SWAG | 85.0 |
| ESIM + ELMo (best from Zellers et al. 2018a) | SWAG | 59.2 |
| BERT Large | SWAG | 86.3 |
| BERT Large (trained on SWAG only) | CODAH | 42.1 |
| GPT-1 (trained on SWAG only) | CODAH | 38.1 |
| BERT Large (trained on SWAG and CODAH) | CODAH | 64.5 |
| GPT-1 (trained on SWAG and CODAH) | CODAH | 65.3 |
| BERT Large (trained on CODAH only) | CODAH | 28.4 |
| GPT-1 (trained on CODAH only) | CODAH | 53.9 |
BERT surpasses the performance of human experts on SWAG, hinting it does not possess human-equivalent commonsense
and rather exploits limitations of the dataset17
.
The results on CODAH, which is a more challenging extension of SWAG seem more sensible, irrespective of the
particular training set.
If you are curious, how BERT and GPT perform on other datasets, here’s a quick summary of some results on other benchmarks presented before.
BERT achieves 55.9% accuracy on CommonsenseQA14 , while GPT reaches 45.5% accuracy. Both results are still relatively low in comparison with the human performance of 88.9%, possibly indicating a difficult dataset.
Rajani et al. (2019)16 test on CommonsenseQA v1.11 (which is said to be more challenging then the original CQA) while training on their own dataset CoS-E. They achieve 55.7% accuracy with their own CAGE-reasoning system compared to a BERT baseline of 56.7%. If provided with additional open-ended human explanations during training, BERT reaches an accuracy of 58.2% (CoS-E-open-ended). The authors also report performances on CQA v1.0.
For results on other benchmarks, please read the respective paper.
Now we’ll have a closer look at Commonsense
Reasoning beyond Natural Language Processing.
CR in Computer Vision and Multimodality
Commonsense Reasoning has recently made it’s debut in the field of Multimodality, more explicitly in the joint application of both images and text.
Visual Commonsense Reasoning
Zellers et al. (2018b)24 introduced the task of Visual Commonsense Reasoning and constructed a dataset along with it. Their approach partly builds upon their prior paper that introduced the SWAG dataset (Zellers et al. 2018a)13 .
A model is provided with an image, a list of regions and a question. In a two-step Question Answering approach it has to choose the right answer for the question and a reasonable rationale to justify its answer.

To enable clean evaluation, the task is formulated as two-step multiple choice Question Answering approach Q
-> AR. Each subtask consists of an image and:
- a sequence of object detections
- a query
- a set of n responses
The first subtask is framed as Q -> A and the query consists of the question while the answers choices
represent the set of n responses.
QA -> R is the reasoning subtask – in the end nothing more
than another Question Answering task. This time, the query is made up of the question concatenated with the right
answer. The responses are the provided rationales.
To collect questions, correct answers and correct rationales, the authors made use of crowd-sourcing while
continously probing the quality of the data.
However, also retrieving the incorrect choice via crowd-sourcing was
a) expensive and b) had the risk of annotation artifacts (subtle patterns injected unknowingly into the data by the
workers).
Therefore, the authors made use of a technique called ‘Adversarial Matching’, where the incorrect
answers or counterfactuals have to be as relevant as possible for the given query but at the same time not too
similar to the correct response or rationale. An illustration of that can be seen below.
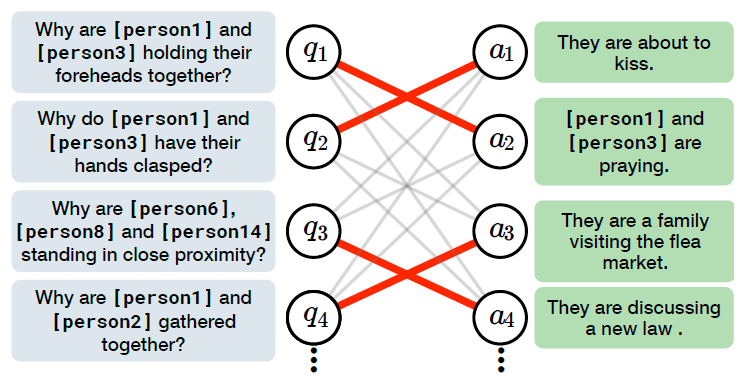
Image from Zellers et al. (2018b)24 : An overview of Adversarial Matching; incorrect reponses are obtained via maximum-weight bipartite matching.
For further details on the construction of the dataset e.g. regarding the selection of the images, details about the crowd-sourcing process or Adversarial Matching, please take a look at the paper.
Next we’ll take a look at the performance of several models on the dataset. Zellers et al. have provided a leaderboard on their website along with their first
experiments in November 2018.
Within a year several other models entered the leaderboard and quickly had beated
the original model of Zellers et al. The table below shows a comparison of the performance of selected leaderboard
entries (accuracy %):
| Model | Q -> A | QA -> R | Q -> AR |
| Humans | 91.0 | 93.0 | 85.0 |
| UNITER-large* | 79.8 | 83.4 | 66.8 |
| ViLBERT* | 76.4 | 78.0 | 59.8 |
| VL-BERT | 75.8 | 78.4 | 59.7 |
| Unicoder-VL* | 76.0 | 77.1 | 58.6 |
| R2C | 65.1 | 67.3 | 44.0 |
The value for human performance was provided by Zellers et al. (2018b) along with the dataset
and their experiments. R2C is their original model which was soon surpassed by several other
models, all of them making use of language models and most of them using ensembling (marked with *). If you are
interested in a particular approach, please read the respective paper.
As we have already seen in Commonsense Reasoning for NLP, language models run the risk of exploiting limitations of datasets and not really learning commonsense. With the quick success of several such models in the field of Multimodality and considering this weakness, one has to scrutinize the performance of every model that attempts Commonsense Reasoning – be it in NLP, CV or in the union of both.
Ongoing research and your part in it
While we have observed a huge improvement in performance of Commonsense Reasoning systems with the advent of Transformer models in NLP and the field of Multimodality, research is far from over. Language models have been shown to exploit some of the available benchmarks while failing on others, making it obvious that those models currently don’t really have an understanding of commonsense.
Furthermore, there’s still reason to develop additional benchmarks to test the Commonsense Reasoning ability of systems. After all, the available benchmarks only require specific types of reasoning and by far not all that we see throughout natural language.
Besides that, there’s still an active branch of research dedicated to more ‘traditional methods’, mostly involving the incorporation of knowledge bases and logical representation into models.4 23 Especially for (but not limited to) reasoning about sciences like physics, these approaches are well-justified despite not being overly successful.
On top of that, there’s also ongoing research on Commonsense Reasoning in the field of Computer Vision and in multimodal approaches, incorporating NLP and CV. With the latter also recently making use of the Transformer and considering the problems of Transformers that have been shown in NLP, the question remains what our models really learn.
In addition to that, in the area of Commonsense Reasoning about videos like movies, research has barely scratched the surface. There have been attempts to provide basic Commonsense Reasoning video datasets25 , but we are far from reaching a deep understanding of media like movies, involving various kinds of reasoning. An example for that is the horsehead scene from the movie The Godfather, that involves several steps of reasoning.3

If this blog post ignited or fueled your interest for Commonsense Reasoning, there are several places to start
out:
AllenAI has built a team named MOSAIC, that has provided the field
with invaluable contributions like Visual Commonsense Reasoning24
, SWAG13
, Event2Mind18
, WinoGrande26
and many more.27
Also, there has been the attempt to cover
progress in NLP in form of a Github repository created
by Sebastian Ruder. It has a section dedicated to
CR, covering some systems’ performances on several CR benchmarks.
But most of all, one should keep an eye
on all those papers that are published continously in the field. Hopefully this post gave you a good idea where to
start for that matter.
Commonsense Reasoning is a very interesting and challenging area of research. It will be exciting to see what the future of the field will look like and if it will bring machines closer to human reasoning and behaviour.
- Liu, Hugo, and Push Singh. “ConceptNet—a practical commonsense reasoning tool-kit.” BT technology journal 22.4 (2004): 211-226, https://www.media.mit.edu/publications/bttj/Paper23Pages211-226.pdf
- Davison, Joe, Joshua Feldman, and Alexander M. Rush. “Commonsense knowledge mining from pretrained models.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019, https://www.aclweb.org/anthology/D19-1109.pdf
- Davis, Ernest, and Gary Marcus. “Commonsense reasoning and commonsense knowledge in artificial intelligence.” Communications of the ACM 58.9 (2015): 92-103, https://dl.acm.org/doi/pdf/10.1145/2701413
- Davis, Ernest. “Logical Formalizations of Commonsense Reasoning: A Survey.” Journal of Artificial Intelligence Research 59 (2017): 651-723, https://pdfs.semanticscholar.org/5601/90715c762b034ddb0e36ee1484c38211c847.pdf
- Clark, Peter, and Oren Etzioni. “My Computer is an Honor Student-but how Intelligent is it? Standardized Tests as a Measure of AI.” , https://pdfs.semanticscholar.org/bcfd/f6d906f4c5214ff25f1c71ec6ffb18a791e0.pdf
- Bar-Hillel, Yehoshua. “The Present Status of Automatic Translation of Languages.” Advances in Computers. Vol. 1. Elsevier, 1960. 91-163.
- Lenat, Douglas B. “CYC: A large-scale investment in knowledge infrastructure.” Communications of the ACM 38.11 (1995): 33-38, https://dl.acm.org/doi/pdf/10.1145/219717.219745
- Miller, George A. “WordNet: a lexical database for English.” Communications of the ACM 38.11 (1995): 39-41, https://dl.acm.org/doi/pdf/10.1145/219717.219748
- Kocijan, Vid, et al. “A Review of Winograd Schema Challenge Datasets and Approaches.” arXiv preprint arXiv:2004.13831 (2020), https://arxiv.org/pdf/2004.13831.pdf
- Levesque, Hector, Ernest Davis, and Leora Morgenstern. “The winograd schema challenge.” Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning. 2012.
- Marcus, Gary, and Ernest Davis. Rebooting AI: Building artificial intelligence we can trust. Pantheon, 2019.
- Mostafazadeh, Nasrin, et al. “A Corpus and Cloze Evaluation for Deeper
Understanding of Commonsense Stories.” Proceedings of the 2016 Conference of the North American Chapter
of the Association for Computational Linguistics: Human Language Technologies. 2016,
https://www.aclweb.org/anthology/N16-1098.pdf - Zellers, Rowan, et al. “SWAG: A Large-Scale Adversarial Dataset for Grounded Commonsense Inference.” Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018, https://www.aclweb.org/anthology/D18-1009.pdf
- Talmor, Alon, et al. “CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge.” Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019, https://www.aclweb.org/anthology/N19-1421.pdf
- Dua, Dheeru, et al. “DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs.” Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019, https://www.aclweb.org/anthology/N19-1246.pdf
- Rajani, Nazneen Fatema, et al. “Explain Yourself! Leveraging Language Models for Commonsense Reasoning.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019, https://www.aclweb.org/anthology/P19-1487.pdf
- Chen, Michael, et al. “CODAH: An Adversarially-Authored Question Answering Dataset for Common Sense.” Proceedings of the 3rd Workshop on Evaluating Vector Space Representations for NLP. 2019, https://www.aclweb.org/anthology/W19-2008.pdf
- Rashkin, Hannah, et al. “Event2Mind: Commonsense Inference on Events, Intents, and Reactions.” Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018, https://www.aclweb.org/anthology/P18-1043.pdf
- Sap, Maarten, et al. “Socialiqa: Commonsense reasoning about social interactions.” arXiv preprint arXiv:1904.09728 (2019), https://arxiv.org/pdf/1904.09728
- Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017, https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
- Radford, Alec, et al. “Improving Language Understanding by Generative Pre-Training.” (2018), https://pdfs.semanticscholar.org/cd18/800a0fe0b668a1cc19f2ec95b5003d0a5035.pdf
- Devlin, Jacob, et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019, https://www.aclweb.org/anthology/N19-1423.pdf
- Marcus, Gary. “The next decade in AI: four steps towards robust artificial intelligence.” arXiv preprint arXiv:2002.06177 (2020), https://arxiv.org/ftp/arxiv/papers/2002/2002.06177.pdf
- Zellers, Rowan, et al. “From Recognition to Cognition: Visual Commonsense Reasoning.” arXiv preprint arXiv:1811.10830 (2018), https://arxiv.org/pdf/1811.10830.pdf
- Goyal, Raghav, et al. “The” Something Something” Video Database for Learning and Evaluating Visual Common Sense.” ICCV. Vol. 1. No. 4. 2017, http://openaccess.thecvf.com/content_ICCV_2017/papers/Goyal_The_Something_Something_ICCV_2017_paper.pdf
- Sakaguchi, Keisuke, et al. “WINOGRANDE: An adversarial winograd schema challenge at scale.” arXiv preprint arXiv:1907.10641 (2019), https://arxiv.org/pdf/1907.10641.pdf
- https://mosaic.allenai.org/publications



